Connaissances basiques en R. Si vous ne faites pas la différence entre un test exact de Fisher et le test du Chi‑2, cela ne devrait pas poser de problème.
Euh, bah c'est tout !
Introduction
Si l'on s'en réfère à la définition :
Un informaticien, et a fortiori un bioinformaticien, fera tout pour mettre en œuvre des stratégies lui permettant d'automatiser les tâches répétitives qui lui incombe.
Plusieurs avantages à cela, i/ rallonger les pauses café, ii/ profiter du temps gagné pour regarder la guerre des étoiles directement sur le terminal :
telnet towel.blinkenlights.nl
Je vous rassure, le but ici n'est pas d'apprendre à réaliser des films en caractères ASCII, chose très fastidieuse et dénuée de toute relation avec la bioinformatique.
Nous allons cependant voir comment à l'aide d'une petite dose de Markdown et de quelques commandes R, il va être possible de générer de façon automatique des beaux rapports d'analyses de données. Cela va nous permettre de réaliser des analyses reproductibles et réutilisables (par exemple, sur de nouveaux jeux de données).
Préparation
Avant de commencer la pratique, quelques petites préparations s'imposent.
Étape n°1, installer le package magique : Rmarkdown (qui est en fait une surcouche de knitr et pandoc)
package.install("rmarkdown",DEPENDANCIES=T)
Ce petit bijou de technologie sera notre fidèle allié dans la bataille contre les forces du mal des activités répétitives.
Étape n°2, créer un nouveau fichier et l'ouvrir dans l'éditeur de texte de votre choix. On ne va pas entrer dans le débat, mais Vi est quand même "le meilleur éditeur du monde" surtout lorsqu'il est épaulé par le plugin vim-r-plugin qui le transforme en véritable IDE pour R. Les moins barbus préféreront utiliser RStudio qui intègre parfaitement la rédaction des documents Rmarkdown.
C'est dans ce fichier que nous allons rédiger notre rapport d'analyse au format Markdown. Pour ceux qui ne sont pas familier avec Markdown, c'est un langage de description syntaxique qui permet de très simplement structurer un document, avec des titres, des liens, des images, des listes, du texte en gras/italique, des tableaux... C'est un peu comme du LaTeX ou du HTML mais sans les balises complexes et les formules compliquées. C'est simplement du texte brut facile à lire et à écrire.
Dans ce document nous allons pouvoir écrire le texte de notre rapport d'analyse et l'entremêler avec des commandes R. Ces dernières seront uniquement évaluées à la génération de façon à insérer les résultats produits dans le document final. L'objectif étant d'écrire un rapport pré-formaté qui va pouvoir être ré-généré avec des données différentes. Pour ceux qui parlent le Python couramment, il existe une solution similaire pour ce langage : iPython Notebook.
Plutôt qu'un long discours, passons à la pratique.
La pratique !
Nous allons tout d'abord introduire au début de notre document quelques métadonnées au format YAML afin d'ajouter un titre bien assumé, le nom de son altesse, une date actuelle et quelques réglages sur le formatage du rapport qui sera produit. Ici, nous allons générer un PDF (compilé à l'aide d'une distribution LaTeX) avec une table des matières. Bien évidement, d'autres formats de sortie sont disponibles comme HTML, doc/docx (Word) ou même sous forme de présentation avec Beamer Latex ou io-slides. Ces deux derniers sont des templates qui permettent de générer des présentations en PDF (Beamer Latex) ou en HTML (io-slides). Il existe également un tas d'options pour personnaliser l'aspect final de votre rapport.
---
title: "Un merveilleux rapport d'analyse"
author: "Elisabeth II"
date: March 22, 2005
output:
pdf_document:
toc: true
---
Maintenant, nous allons ajouter une première section à ce document afin de vanter les magnifiques analyses qui vont suivre :
# Introduction
Dans ce **magnifique** document, nous allons analyser un ensemble d'annotations récupérées sur la base de données *Ensembl*.
Dans ce rapport nous allons découvrir :
- un magnifique graphique
- un exceptionnel tableau
- et un score de corrélation de Pearson.
Dans le formatage Markdown, le caractère
#
permet d'introduire un titre de niveau 1, deux dièses auraient introduit un titre de niveau 2, etc. Les doubles
**
qui entourent un mot permettent de mettre le texte en gras et les simples
*
correspondent à l'italique. Enfin une liste à puces est simplement représentée par des tirets. Pour plus d'informations sur ce langage, direction la page officielle.
Avant de commencer les choses sérieuses, l'analyse que nous allons mener va se baser sur l'ensemble des annotations (au format GTF) du C. elegans récupérées ici sur Ensembl.
Afin d'inclure du code R nous allons insérer des R chunks :
Un R chunk est un couple de balises entre lesquelles nous allons placer du code R. Ce dernier ne sera interprété qu'à la compilation du document et le résultat produit par le code (plot, tableau, variable) sera inséré dans le document en place du chunk.
Voila un exemple de R chunk qui affiche Hello world :
{r}
print("Hello world")
Il existe également la version "inline" du R chunk, qui permet d'intégrer un résultat numérique directement dans une phrase :
r 2*3*7is the answer to life, the universe, and everything.
Un R chunk ne produit pas forcément de résultats visibles. Certain chunk peuvent uniquement permettre d'exécuter du code R dit "silencieux".
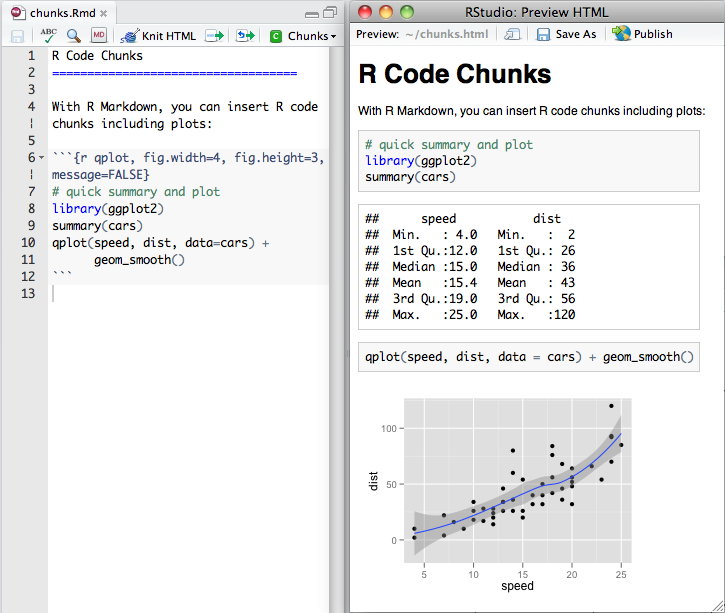
Un document Rmarkdown et sa prévisualisation dan RStudio.
Un cas courant d'utilisation de chunk silencieux correspond au chargement de bibliothèques et/ou de fichiers, comme ce sera le cas de notre premier R chunk :
entre les accolades qui permet d'indiquer à knitr de ne pas afficher les lignes de code dans le document final.
Trois commandes sont présentes dans ce chunk, la première permet de charger la bibliothèque ggplot2 qui va s'occuper de générer nos beaux graphiques, la seconde permet d'importer notre fichier d'annotation dans un Dataframe (nom donné à un tableau à double entrée dans R) en se limitant aux 1000 premières lignes car on n'a pas toute la nuit ! Enfin, la troisième commande permet de définir le nom des colonnes du Dataframe.
Maintenant ces initialisations faites, nous allons pouvoir démarrer notre analyse ! Il est important de noter que même si les chunks sont physiquement séparés les uns des autres, ils sont en fait exécutés les uns à la suite des autres dans une même session R. Cela signifie que les variables déclarées dans un chunk (comme ici
df
), sont utilisables dans tout le reste du document.
Nous pouvons maintenant intégrer un premier graphique sur la fréquence des différents types d'annotations (gène, exon, transcrit) :
# Analyse des annotations du C. elegans {r echo=FALSE}
ggplot(df,aes(df$feature)) + geom_bar() + ggtitle("Fréquence des annotations")
Si vous souhaitez en savoir plus sur ggplot, leur site web déborde d'exemples.
À la suite de ce graphique nous allons intégrer un tableau formaté correspondant à un extrait des annotations contenues dans notre Dataframe :
{r echo=FALSE, results='asis'}
knitr::kable(head(df[,1:5]),caption="Aperçu des annotations")
Afin de générer notre tableau nous avons utilisé la fonction
kable
du package knitr qui permet de transformer notre Dataframe en un tableau formaté à la sauce Markdown. Il a également été nécessaire d'ajouter l'option
results='asis'
pour spécifier à Rmarkdown de n'appliquer aucun post-traitement sur le résultat produit par ce chunk.
Enfin nous allons finir cette belle analyse avec une petite mesure de corrélation (avec la méthode de Pearson) entre les positions de début et de fin des annotations, qui, comme on pourrait l'attendre est très bonne.
La corrélation de Pearson réalisée sur les positions (début, fin) des annotations est de r cor(df$start,df$end,method="pearson"). Ce résultat est très élevé, comme on aurait pu s'en douter.
Maintenant, il ne nous reste plus qu'à générer le document final à l'aide de la commande
rmarkdown::render("my-first-report.Rmd")
et d'admirer le résultat !
Pour ceux qui travaillent sous RStudio un bouton "knit PDF" est directement intégré à l'interface graphique.
Conclusion
Si vous êtes arrivés vivants jusqu'ici, vous avez maintenant toutes les cartes en main pour créer de magnifiques rapports d'analyses reproductibles. Si vous souhaitez en savoir plus, un site regroupant plein de ressources a été mis en place par/pour la communauté. Vous y apprendrez entre autres à écrire des chunks réutilisables, à intégrer des citations et à générer des rapports HTML interactifs.
Pour ceux qui souhaitent aller plus loin, un MOOC (cours en ligne) sur le thème de la "Recherche reproductible" et se basant sur Rmarkdown vient de commencer sur Coursera (jusqu'au 1er juin). Ce cours est dispensé par l'université de Johns Hopkins et devrait vous permettre d'approfondir le sujet avec un cours de grande qualité.
Un grand merci à toute l'équipe de Bioinfo-fr et en particulier à nahoy, hedjour, Yoann, m4rsu, Nico M. et Nolwenn pour leur relecture, leurs conseils et leur aide pour la publication de mon premier article sur Bioinfo-fr.
Après un diplôme d'ingénieur en informatique et un Master de bioinformatique en poche, je réalise aujourd'hui une thèse en biologie computationnelle portant sur l'étude des transcriptomes dans la recherche en cancérologie à l'aide des technologies haut débit (RNA-Seq). À la fois développeur, algorithmicien et bio-analyste, je trouve mon bonheur dans la bioinformatique au sens large.
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations des appareils. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les ID uniques sur ce site. Le fait de ne pas consentir ou de retirer son consentement peut avoir un effet négatif sur certaines caractéristiques et fonctions.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’internaute, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou la personne utilisant le service.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’internautes afin d’envoyer des publicités, ou pour suivre l’internaute sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.



Laisser un commentaire