

Langage : shell
Commande présentée : join
Niveau : débutant
Présentation de la commande join
La commande join est disponible nativement sur les systèmes d'exploitation GNU/Linux. Il s'agit d'une commande POSIX et elle est donc présente sur tous les systèmes d'exploitation UNIX et UNIX-Like. La plupart des gens utilisent cette commande pour récupérer les lignes communes entre deux fichiers mais elle ne se limite pas à ce seul cas.
Join vous permet de fusionner des champs (colonnes) précis de deux fichiers textes et d'en récupérer la liste des données communes ou encore de vous afficher un résultat proche de ce que vous pourriez faire en SQL avec une requête JOIN.
Dans ce billet je vais vous montrer différentes façons dont on pourrait se servir de cette commande pour récupérer de l'information biologique à partir de données textuelles.
Préparation des fichiers
Nous nous proposons de trouver les identifiants UniProt des gènes d'Escherichia coli identifiés par le NCBI pour le cycle de Krebs. Pour cela il faut récupérer des données dans différentes banques de données.
Récupération des données sur les gènes d'Escherichia coli :
|
1 |
wget ftp ://ftp.ncbi.nlm.nih.gov/gene/DATA/GENE_INFO/Archaea_Bacteria/Escherichia_coli_str._K-12_substr._MG1655.gene_info.gz |
Récupération des données UniProt d'Escherichia coli :
|
1 |
wget ftp ://ftp.uniprot.org/pub/databases/uniprot/current_release/knowledgebase/idmapping/by_organism/ECOLI_83333_idmapping.dat.gz |
Liste des gènes du cycle de Krebs : (fichier : genes_cycle_krebs_ecoli.txt, source KEGG)
Ces fichiers présentent des données sous forme de colonnes.
Colonnes du fichier du NCBI :
- Numéro de taxon
- Identifiant du gène (GeneID)
- Symbole du gène
- Localisation du gène
- Synonymes
- Références croisées
- Chromosome
- Localisation sur la carte chromosomique
- Description
- Type de gène
- Symbole provenant de l'autorité de nomenclature
- Nom complet fourni par l'autorité de nomenclature
- Statut de la nomenclature
- Autres désignations
- Date de modification
Colonnes du fichier d'UniProt :
- Numéro d'accession UniProt
- Base de données d'origine
- Identifiant de la base de données d'origine
Dans un premier temps, nous allons extraire les informations sur les gènes à l'aide de la commande grep, comme décrite dans ce billet du blog :
|
1 |
grep -w -f genes_cycle_krebs_ecoli.txt Escherichia_coli_str._K-12_substr._MG1655.gene_info > geneinfo_krebs_ecoli.tsv |
Maintenant que les fichiers sont préparés, nous allons pouvoir faire deux exercices :
- une fusion simple des fichiers ;
- une fusion des fichiers avec sélection des colonnes d'intérêt.
Fusion simple
Avant de fusionner les fichiers, vous devez vous assurer qu'ils sont triés de la même façon sur les colonnes à fusionner. Par défaut la commande join fusionne sur la première colonne mais il est possible de préciser les colonnes pour chaque fichier.
Voici un exemple simple pour illustrer dans un premier temps la commande join :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
cat fichier1.txt #ID Prénom 1 Arnaud 2 Constance 3 Julie 4 Constantin cat fichier2.txt #ID Console 1 Playstation 3 Nintendo DS 4 Wii-U |
La commande join va afficher sur chaque ligne le #ID, le Prénom et la Console pour chaque individu (les tabulations sont remplacées par des espaces, c'est le comportement par défaut de la commande) :
|
1 2 3 4 5 |
join fichier1.txt fichier2.txt 1 Arnaud Playstation 3 Julie Nintendo DS 4 Constantin Wii-U |
Dans nos exemples biologiques, nous travaillerons sur les identifiants GeneID des deux fichiers, soit la colonne 3 pour le fichier d'UniProt (option -1 3) et la colonne 2 pour le fichier du NCBI (option -2 2). De plus, nous avons besoin de trouver les données qui correspondent au NCBI dans le fichier d'UniProt. Dans un premier temps nous devons trier les colonnes de la même façon pour chacun des fichiers :
|
1 2 |
grep -w "GeneID" ECOLI_83333_idmapping.dat | sort -k 3,3n > ECOLI_83333_idmapping2.dat sort -k 2,2n geneinfo_krebs_ecoli.tsv > geneinfo_krebs_ecoli2.tsv |
La fusion simple se fait ainsi :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
join -13 -22 ECOLI_83333_idmapping2.dat geneinfo_krebs_ecoli2.tsv 944794 P06959 GeneID 511145 aceF b0115 ECK0114|JW0111 EcoGene :EG10025 - - pyruvate dehydrogenase, dihydrolipoyltransacetylase component E2 protein-coding - - - - 20130526 944834 P0AFG8 GeneID 511145 aceE b0114 ECK0113|JW0110 EcoGene :EG10024 - - pyruvate dehydrogenase, decarboxylase component E1, thiamin-binding protein-coding - - - - 20130526 944854 P0A9P0 GeneID 511145 lpd b0116 ECK0115|JW0112|dhl|lpdA EcoGene :EG10543 - - lipoamide dehydrogenase, E3 component is part of three enzyme complexes protein-coding - - - - 20130526 [...] 948666 P0AC47 GeneID 511145 frdB b4153 ECK4149|JW4114 EcoGene :EG10331 - - fumarate reductase (anaerobic), Fe-S subunit protein-coding - - - - 20130526 948667 P00363 GeneID 511145 frdA b4154 ECK4150|JW4115 EcoGene :EG10330 - - fumarate reductase (anaerobic) catalytic and NAD/flavoprotein subunit protein-coding - - - - 20130526 948668 P0A8Q3 GeneID 511145 frdD b4151 ECK4147|JW4112 EcoGene :EG10333 - - fumarate reductase (anaerobic), membrane anchor subunit protein-coding - - - - 20130526 join : geneinfo_krebs_ecoli2.tsv :29 : n'est pas trié : 511145 4056026 icdC b4519 ECK1146|JW5173|icd EcoGene :EG10009 - - pseudo pseudo - –- 20130526 948680 P0A8Q0 GeneID 511145 frdC b4152 ECK4148|JW4113 EcoGene :EG10332 - - fumarate reductase (anaerobic), membrane anchor subunit protein-coding - - - - 20130526 join : ECOLI_83333_idmapping2.dat :4209 : n'est pas trié : P19768 GeneID 1238726 |
Décortiquons les options spécifiées à la commande join :
- -13 : fichier 1 (ECOLI_83333_idmapping2.dat), colonne 3
- -22 : fichier 2 (geneinfo_krebs_ecoli2.tsv), colonne 2
Les erreurs soulevées (join : ECOLI_83333_idmapping2.dat:4209 : n'est pas trié) sont dues au fait que, dans le fichier UniProt, un même identifiant de gène peut être associé à plusieurs identifiants UniProt –dois-je vous rappeler qu'un gène peut coder pour plus d'une protéine ?
Dans le résultat affiché, la première colonne correspond à la colonne commune aux deux fichiers, les colonnes 2 et 3 correspondent aux colonnes 1 et 2 du fichier UniProt, les autres colonnes correspondent aux colonnes du fichier du NCBI, avec la colonne 2 en moins (elle est fusionnée dans la colonne 1 du résultat).
Fusionner les fichiers et n'afficher que certaines colonnes
Comme vous pouvez le constater, il y a beaucoup de colonnes, ce qui peut être lourd à traiter par la suite. On va donc n'afficher que certaines colonnes afin de faciliter d'autres éventuelles manipulations sur ces données.
En reprenant notre exemple simpliste, voici ce que nous pourrions faire avec les fichiers :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
cat fichier1.txt #ID Prénom 1 Arnaud 2 Constance 3 Julie 4 Constantin cat fichier2.txt #ID Console Constructeur 1 Playstation Sony 3 Nintendo DS Nintendo 4 Wii-U Nintendo |
Ici nous ne voulons afficher que les prénoms et le constructeur de chaque console utilisée pour chaque personne en possédant une, nous allons donc afficher la colonne 2 du fichier 1 et la colonne 3 du fichier 2 (option -o). De plus, comme la console Nintendo DS contient un espace dans son nom, nous devons préciser à la commande join d'utiliser le séparateur tabulation (option -t) :
|
1 2 3 4 5 |
join -t $'\t' -o 1.2,2.3 fichier1.txt fichier2.txt #Prénom Constructeur Arnaud Sony Julie Nintendo Constantin Nintendo |
Dans notre exemple avec les données biologiques, nous allons sélectionner, pour le fichier du NCBI, les colonnes suivantes :
- GeneID, colonne 2
- Symbole, colonne 3
- Synonyms, colonne 4
- Description, colonne 9
- Type de gène, colonne 10
Pour le fichier UniProt, nous allons sélectionner la colonne 1 qui correspond à l'identifiant UniProt.
En reprenant la première commande et en précisant les colonnes d'intérêt, voici la nouvelle commande à utiliser et son résultat :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
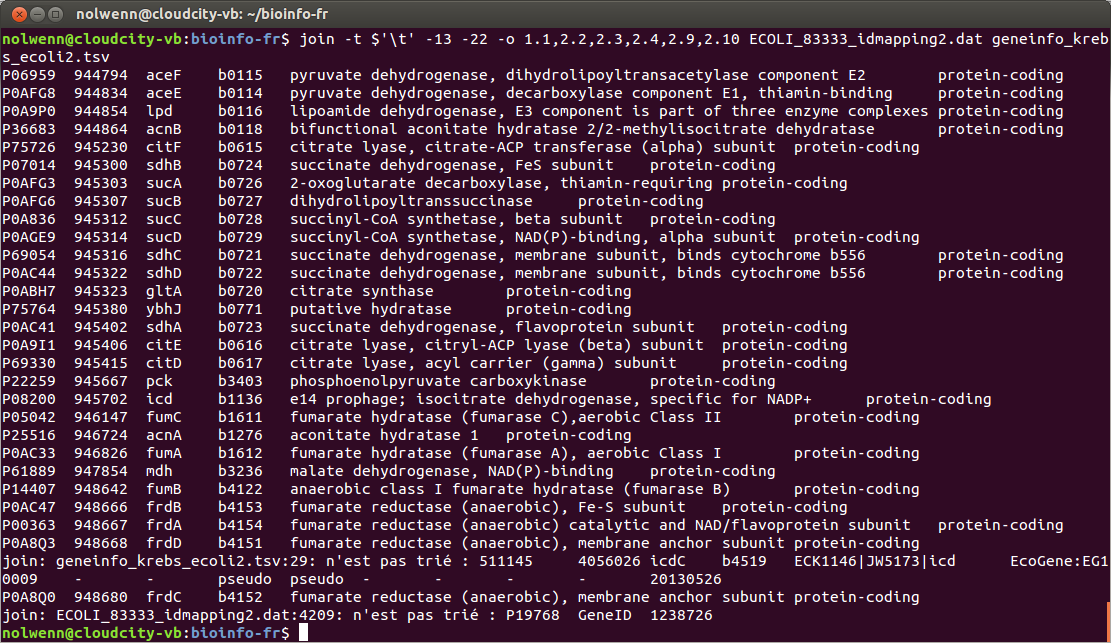
join -t $'\t' -13 -22 -o 1.1,2.2,2.3,2.4,2.9,2.10 ECOLI_83333_idmapping2.dat geneinfo_krebs_ecoli2.tsv P06959 944794 aceF b0115 pyruvate dehydrogenase, dihydrolipoyltransacetylase component E2 protein-coding P0AFG8 944834 aceE b0114 pyruvate dehydrogenase, decarboxylase component E1, thiamin-binding protein-coding P0A9P0 944854 lpd b0116 lipoamide dehydrogenase, E3 component is part of three enzyme complexes protein-coding [...] P0AC47 948666 frdB b4153 fumarate reductase (anaerobic), Fe-S subunit protein-coding P00363 948667 frdA b4154 fumarate reductase (anaerobic) catalytic and NAD/flavoprotein subunit protein-coding P0A8Q3 948668 frdD b4151 fumarate reductase (anaerobic), membrane anchor subunit protein-coding join : geneinfo_krebs_ecoli2.tsv :29 : n'est pas trié : 511145 4056026 icdC b4519 ECK1146|JW5173|icd EcoGene :EG10009 - - pseudo pseudo - –- 20130526 P0A8Q0 948680 frdC b4152 fumarate reductase (anaerobic), membrane anchor subunit protein-coding join : ECOLI_83333_idmapping2.dat :4209 : n'est pas trié : P19768 GeneID 1238726 |
Explication sur les options utilisées :
- -o : précise la liste des colonnes à afficher. Le premier chiffre doit être le numéro du fichier et le second le numéro de la colonne à afficher.
- -t $'\t' : précise à la commande join que les champs sont séparés par des tabulations, nécessaire dans ce cas de figure.
Quand join se prend pour SQL
Vous l'aurez remarqué, la commande de base de join fusionne les fichiers entre eux en n'affichant que les lignes communes. Or dans certains cas vous aimeriez pouvoir conserver les lignes d'un de vos fichiers, afin de voir quelles sont les lignes qui n'ont pas pu être fusionnées. Pour cela, vous pouvez utiliser l'option -a suivie du numéro du fichier pour lequel vous voulez afficher les lignes.
Vous avez pris peu de colonnes et vous avez peur de passer à côté d'une ligne non fusionnée ? Utilisez l'option -e suivie, entre guillemets, d'un mot clé, comme NULL par exemple. Ainsi vous saurez que toutes les lignes qui ont ce mot clé n'ont pas pu être fusionnées.
En voici une illustration avec nos joueurs de consoles préférés, ici nous demandons à join d'afficher toutes les lignes de fichier1.txt et d'ajouter le mot clé "Aucun" lorsque la ligne n'est pas fusionnée avec fichier2.txt :
|
1 2 3 4 5 |
join -a 1 -e "Aucun" -t $'\t' -o 1.2,2.3 fichier1.txt fichier2.txt Arnaud Sony Constance Aucun # Constance n'est pas une joueuse Julie Nintendo Constantin Nintendo |
Conclusion
La commande join est une commande qui effraye certains d'entre nous, or une fois que l'on connaît et que l'on a compris son fonctionnement, il est vraiment possible de s'amuser avec. Ne faites pas la même erreur que moi dans ces exemples, encore que l'erreur a pu vous illustrer les limites de la commande : assurez-vous que la colonne que vous cherchez à fusionner n'aura qu'une seule occurrence pour chaque clé ! Dans mon exemple, si je veux retrouver les informations pour les identifiants UniProt des lignes qui ont généré des erreurs, je vais devoir passer par la commande grep.
J'espère que ce billet aura permis aux plus frileux d'entre vous d'entrevoir les possibilités offertes par cette commande qui mérite que l'on s'y intéresse dans notre domaine.
Pour comprendre un peu mieux les exemples que je vous ai montré, vous pouvez consulter cette page et vous en inspirer, elle m'a fortement aidée dans mes débuts avec cette commande : http://fr.wikipedia.org/wiki/Join_(Unix)
Merci à Bunny, nallias, Clem_ et ZaZo0o pour leur relecture et nos échanges.
Laisser un commentaire