

Intelligence Artificielle, Machine Learning, Deep-Learning, quid du Data-Scientist

Intelligence artificielle (IA), Machine learning (Apprentissage machine, pour les francophones), Deep-learning (Apprentissage profond), autant de termes si étrangers et familiers à la fois… Comment se retrouver dans cette jungle de termes techniques ?
Commençons par définir ce qu'est l'IA. Base de science-fiction pour certains, source d'inquiétudes pour d'autres, nous aborderons l'IA d'un point de vue technique. Inspirée de la biologie et des sciences cognitives, sur fondements mathématiques, l'intelligence artificielle se définit comme un ensemble d'algorithmes visant à reproduire les décisions prises par un être humain dans le but d'accomplir une tâches spécifique.
Qui dit humain, dit apprentissage perceptuel, organisation de la mémoire et le raisonnement critique. En effet, tout algorithme d'IA nécessitera la connaissance de l'Homme, aussi bien dans la préparation, l'étiquetage des données, et leur interprétation.
L'IA oui, mais pour quoi faire ?
Les tâches accomplissables par l'IA sont aussi variées que la définition de l'IA en elle-même, et que le nombre d'approches pour résoudre un problème donné. Les tâches les plus communément résolues à l'aide de l'intelligence artificielle sont : la classification (binaire, multi-classes), la régression, la segmentation d'images (identification des différentes composantes de l'image de manière automatisée), le débruitage de données, la détection d'objets, le traitement du langage naturel, etc. (liste non exhaustive). Pour un peu plus de généralités sur l'apprentissage profond et ses application, c'est ici
Relevons maintenant nos manches et abordons notre premier projet d'IA.
Définition de la problématique
Pour cette introduction, abordons une problématique relativement simple, sur des données simples. Nous allons aujourd'hui nous intéresser à la classification de séquences d'ADN, afin de déterminer si ces séquences sont promotrices ou non (classification binaire). L'idée est donc de proposer à l'entrée de notre réseau une séquence de nucléotides pour obtenir en sortie une classe 0 ou 1, décrivant respectivement les caractères non-promoteurs et promoteurs de notre séquence (0 la séquence n'est pas promotrice, 1 elle l'est). Les données seront découpées en deux fichiers : l'un contenant les séquences promotrices, le second contenant les séquences non promotrices. Données disponibles ici, le notebook du code est disponible là.
Préparation des données
Pour ce projet bien que peu complexe, nous utiliserons Google Colab afin de faciliter l'accès aux données et bénéficier de ressources suffisantes. Bien entendu, la démarche est reproductible en local, et avec peut être même plus de performances.
Commençons "monter" notre Drive, afin de pouvoir accéder aux données, définissons-en les chemins, et importons les librairies nécessaires.
from google.colab import drive
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import keras
from keras.layers import Dense, Dropout, Flatten, Conv1D, MaxPooling1D
from keras import regularizers
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import train_test_split
# montage du Drive
drive.mount('/content/drive')
# definition des chemins d'acces aux fichiers
work_folder = "/content/drive/MyDrive/Promoters_classification/"
non_promoters_set = work_folder + "NonPromoterSequence.txt"
promoter_set = work_folder + "PromoterSequence.txt"Les données n'ayant pas un format "standard" pour les librairies classiques, il va être nécessaire de les formater correctement. Remarquons qu'il s'agit ici de données type fasta, le séparateur sera donc un chevron '>'. Un article de bioinfo-fr sur le format fasta à cette adresse.
Nous souhaitons nous ramener à un tableau à deux colonnes : séquence, label. De plus, nos données sont consignées dans deux fichiers différents qu'il va falloir assembler. Réalisons donc cela.
# Chargement nettoyage et labelisation des données de sequences non promotrices
df_non_promoters = pd.read_csv(non_promoters_set, sep = '>', )
df_non_promoters.dropna(subset=['Unnamed: 0'], how='all', inplace=True)
df_non_promoters.reset_index(inplace = True)
df_non_promoters.drop(['EP 1 (+) mt:CoI_1; range -400 to -100.', 'index'], axis = 1, inplace=True) #data cleaning after error found
df_non_promoters.rename(columns={'Unnamed: 0': "sequence"}, inplace = True)
df_non_promoters['label'] = 0
# Chargement, nettoyage et labelisation des données de sequences promotrices
df_promoters = pd.read_csv(promoter_set, sep = '>', )
df_promoters.dropna(subset=['Unnamed: 0'], how='all', inplace=True)
df_promoters.reset_index(inplace = True)
df_promoters.drop(['EP 1 (+) mt:CoI_1; range -100 to 200.', 'index'], axis = 1, inplace=True) #data cleaning after error found
df_promoters.rename(columns={'Unnamed: 0': "sequence"}, inplace = True)
df_promoters['label'] = 1
# Concatenation des deux tableaux
df = pd.concat([df_non_promoters, df_promoters], axis = 0 )
print(f"Shape of the full dataset: {df.shape}")
Shape of the full dataset: (22600, 2)
sequence label
0 TAATTACATTATTTTTTTATTTACGAATTTGTTATTCCGCTTTTAT... 0
1 ATTTTTACAAGAACAAGACATTTAACTTTAACTTTATCTTTAGCTT... 0
2 AGAGATAGGTGGGTCTGTAACACTCGAATCAAAAACAATATTAAGA... 0
3 TATGTATATAGAGATAGGCGTTGCCAATAACTTTTGCGTTTTTTGC... 0
4 AGAAATAATAGCTAGAGCAAAAAACAGCTTAGAACGGCTGATGCTC... 0
Nous nous retrouvons donc avec un tableau à deux colonnes contenant 22600 séquences et leurs labels. Comme toute bonne analyse de données, il va être nécessaire de nettoyer ces dernières. Dans notre cas, il s'agira de retirer les séquences présentant des nucléotides marqués comme "N".
nb_sequences_to_drop = 0
rows_indexes_to_drop = list()
for idx, seq in enumerate(df['sequence']):
if 'N' in seq:
nb_sequences_to_drop +=1
# display(df.loc[df['sequence'] == seq])
rows_indexes_to_drop.append(idx)
print(f"Number of sequence to be dropped : {nb_sequences_to_drop}")
print(f"Rows to be dropped : {rows_indexes_to_drop}")
print(f"Shape of the data before dropping sequences containing Ns : {df.shape}")
df.drop(rows_indexes_to_drop, inplace = True)
print(f"Shape of the data after dropping sequences containing Ns : {df.shape}")
Number of sequences to be dropped : 1 Rows to be dropped : [1822] Shape of the data before dropping sequences containing Ns : (22600, 2) Shape of the data after dropping sequences containing Ns : (22598, 2)
Nous allons construire un réseau à convolution, basé sur des données textuelles. Ces données, n'étant pas directement traitables par ce type de réseau, il va falloir en changer la représentation. Une façon classique de faire est d'utiliser la stratégie de "one-hot encoding".

L'idée est de caractériser (pour notre problématique) chacune des bases de la séquence par un quadruplet de valeurs étant soit 0, soit 1, sachant que seule une des valeurs peut être à 1. Ainsi, les 4 bases sont encodées comme : A : {1, 0, 0, 0}, T : {0, 1, 0, 0} , C : {0, 0, 1, 0} et G : {0, 0, 0, 1}. Dans notre cas, nos séquences étant de longueur 301, la transformation donnera donc naissance pour une matrice de taille 4 x 301. A l'échelle du jeu de données, les dimensions seront de 22598 x 301 x 4. Réalisons donc notre encodage.
sequence = list(df.loc[:, 'sequence'])
encoded_list = []
def encode_seq(s):
Encode = {'A':[1,0,0,0],'T':[0,1,0,0],'C':[0,0,1,0],'G':[0,0,0,1]}
return [Encode[x] for x in s]
for i in sequence:
x = encode_seq(i)
encoded_list.append(x)
X = np.array(encoded_list)
print(f" Shape of one-hot encoded sequences: {X.shape}")
Shape of one-hot encoded sequences: (22598, 301, 4)
Nos données sont maintenant presque prêtes. Il va s'agir de séparer les séquences transformées de leurs labels.
X = X.reshape(X.shape[0],301, 4, 1) # Tensor containing one-hot encoded sequences wich are promotors or not
y = df['label'] # Tensor containing labels for each sequence (0 : sequence is nt a promotor, 1 : sequence is a promotor)
print(y.value_counts())
print(f"Shape of tensor containing sequences one-hot encoded {X.shape}n")
print(f"Shape of tensor containing labels relatives to the sequences : {y.shape}")
if(X.shape[0] != y.shape[0]):
raise ValueError('Sequence tensor and lebels tensor need to have corresponding shapes')
Préparation des jeux de données d'entrainement, de test et de validation
Il est désormais nécessaire de séparer nos données en trois sous-ensembles : entrainement, test et validation. Les données d'entrainement vont permettre au réseau d'ajuster ses poids en fonction de l'erreur entre la prédiction du type de séquence, promotrice ou non, les données de test d'évaluer les performances de l'entrainement et enfin les données de validation d'obtenir les performances du modèles une fois entrainé. Les trois jeux de données doivent être indépendants les uns des autres afin de garantir de ne pas rencontrer un exemple de séquence déjà rencontré à l'entrainement. Il est également nécessaire de s'assurer (si possible) que dans chacun des sets, les différentes classes soient représentées en proportions égales. Préparons nos jeux de données.
# On redimensionne nos données afin qu'elles puissent être traitées par le réseau
X = X.reshape(X.shape[0],301, 4, 1) # Tensor containing one-hot encoded sequences wich are promotors or not
y = df['label'] # Tensor containing labels for each sequence (0 : sequence is nt a promotor, 1 : sequence is a promotor)
print(y.value_counts())
print(f"Shape of tensor containing sequences one-hot encoded {X.shape}n")
print(f"Shape of tensor containing labels relatives to the sequences : {y.shape}")
0 11299 1 11299 Name: label, dtype: int64 Shape of tensor containing sequences one-hot encoded (22598, 301, 4, 1) Shape of tensor containing labels relatives to the sequences : (22598,)
On s'assure que nous disposons bien du même nombre de séquences que de labels. C'est le cas, divisons alors nos données en respectant les strates.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42, stratify = y, shuffle = True, test_size = 0.2) # Split data into train and test with respect of class proportions X_test, X_validation, y_test, y_validation = train_test_split(X_test, y_test, random_state = 42, stratify = y_test, shuffle = True, test_size = 0.5) # Split data into test and validation with respect of class proportions print(y_train.value_counts()) print(y_test.value_counts()) print(y_validation.value_counts())
0 9039 1 9039 Name: label, dtype: int64 0 1130 1 1130 Name: label, dtype: int64 1 1130 0 1130 Name: label, dtype: int64
Construction du modèle
Afin de répondre à notre question, nous allons construire un modèle de type réseau convolutif peu profond, avec une couche de sortie ne disposant que d'un seul neurone qui indique que la séquence est de type promoteur s'il est activé. Pour en savoir plus sur les réseaux de convolution, je vous recommande cette vidéo.
L'apprentissage un problème d'optimisation ?
Les problématiques d'apprentissage, qu'il soit profond ou machine, peuvent être définies comme des problématiques d'optimisation. Il s'agit donc de construire un système, ou modèle au départ "naïf" que nous allons entraîner. Dans notre cas il s'agira de rendre de plus en plus performant notre modèle en l’entraînant à classifier correctement les séquences promotrices des séquences non promotrices. Pour cela nous allons demander au réseau de classer à plusieurs reprises un ensemble d'exemples par lots (ou batches) et évaluer une erreur, laquelle va nous servir à ajuster les coefficients des noyaux de convolutions jusqu'à atteindre un optimum.
Cet optimum correspond au minimum global de la fonction de coût évaluant la quantité d'erreur réalisées dans les tâches de classification du modèle. On ajustera alors ces poids en fonction de l'intensité de cette erreur : plus cette dernière sera élevée, plus les coefficients seront modifiés, à l'inverse moins l'erreur sera grande moins les coefficients seront modifiés. Cette erreur est évaluée en calculant le gradient de la fonction d'erreur, ou plus formellement la dérivée partielle en chaque neurone du réseau en fonction du neurone. Cette même erreur est pondérée par le taux d'apprentissage (learning rate) lequel pondère la force de modification des poids. Ainsi plus le taux d'apprentissage sera faible, plus l'entrainement sera lent, mais plus il aura de chance de converger vers un optimum global.
Comment définir la quantité d'erreur
La quantité d'erreur est évaluée par la fonction de coût (ou Loss). Cette dernière rend compte du nombre de classes mal prédites lors de l'évaluation d'un ensemble de séquences de l'entrainement. Dépendamment des problématiques auxquelles il faut répondre, les fonctions de coût diffèrent notamment par le nombre de classes possibles, les liens qui existent éventuellement entre ces classes.
La quantité d'erreur est évaluée à chaque prédiction de lots de séquences. La dérivée partielle de cette fonction d'erreur sera alors calculée vis à vis de chacun des paramètres du réseau, afin d'ajuster ces derniers en sens "inverse" de cette dérivée. Ainsi lorsque la quantité d'erreurs se stabilise, ou atteint des valeurs très faibles l'ajustement des paramètres est moindre et l'apprentissage pourrait se terminer.
Dans les exemples ci-après la fonction de coût utilisée sera la "Binary Cross-Entropy" rendant compte de l'erreur de classification dans un problème d'optimisation à deux classes.
Vous avez dit convolution ?
La convolution est une opération mathématique sur les matrices. Il s'agit de "mettre en correspondance" une matrice représentant les données, avec une matrice dite "noyau de convolution" (ou kernel). La matrice résultante est le produit matriciel entre la matrice de données et le kernel (à laquelle on ajoute parfois une matrice contenant le poids des biais de chaque neurone).

En se basant sur la première opération de convolution de l'illustration précédente nous aurions :
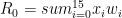
On réalise cette opération de convolution plusieurs fois en faisant glisser le noyau (en rouge) le long de la séquence encodée de dimension 301 x4. Nous utiliserons ici un padding de type valid, qui n'autorise la convolution que dans le cas ou le "recouvrement" de laséquence par le noyau est complet. Ainsi le nombre de convolutions, et par conséquent la taille de la représentation de sortie, seront limités à 298. Le filtre f0 glissera donc d'un pas de 1 sur la séquence et aura 298 positions donnant le à autant d'opérations de convolutions. Finalement pour ce filtre, la dimension de sortie sera de 298x1.
Et nous répétons la même opération pour les 26 autres filtres de f1 à f26. Nous obtenons donc en sortie de cette couche de convolution une représentation de dimension 298x1x27.
Ce résultat de convolution va ensuite subir une opération d'activation, qui revient à rechercher l'image de chacun des éléments de la matrice résultant de la convolution, par la fonction d'activation (ici ReLU pour "Rectified Linear Unit). Cette opération vise à mettre en avant les valeurs/éléments les plus pertinents de la nouvelle représentation après convolution qui seront transmises aux prochaines couches du réseau.
Pool !
Aux couches de convolutions succèdent les couches de pooling. Ces couches visent à sous-échantillonner les résultats des couches convolutionnelles afin de ne garder que l'information pertinente de cette représentation, mais aussi de diminuer la taille de la représentation de la séquence initiale au travers du réseau.
Il existe plusieurs méthodes pour sous-échantillonner les résultats de convolution. L'idée générale est de sélectionner parmi un ensemble plus ou moins grand de valeurs contiguës de la représentation post-convolution. Il convient tout d'abords de définir la taille de cette fenêtre de recherche. Dans l'exemple ci-dessous, cette taille sera de 3. Puis il s'agit de choisir la fonction ou méthode permettant d'extraire une unique valeur de cette fenêtre.
Ce choix peut être la moyenne des valeurs de la fenêtre, la médiane, le minimum, ou encore dans notre cas le maximum.

Ainsi dans notre cas, nous procéderons à l'extraction de valeurs d'intérêts dans une fenêtre glissant le long du vecteur résultat de la convolution, avec une fenêtre de taille 3. Nous utiliserons la fonction max, c'est à dire que nous ne retiendront que la valeur maximale pour une fenêtre de 3 valeurs contiguës, avant de répéter l'opération aux trois suivantes. Avec plus de formalisme mathématique :

Ainsi après sous-échantillonnage par une fenêtre de taille 3, les dimensions de nos 27 représentations post-convolutions seront de divisées par 3.
La notion de champs récepteurs
Comme nous l'avions évoqué en introduction, les réseaux de neurones s’inspirent de la Biologie. Comme nous le savons, dans le système nerveux, les neurones sont connectés en cascade. Certaines neurones reçoivent l'information pré-traitées via les axones de leurs prédécesseurs au niveau du soma. Ainsi pour une neurone donnée, le signal reçu compile l’information transmise par ses prédécesseurs, qui eux-mêmes ont potentiellement reçu un condensé de l'information obtenue par le système perceptif.
Le parallèle est possible avec les réseaux convolutifs. Le premier bloc convolutif (couche de convolution + activation + pooling) voit l'intégralité de la séquence en entrée. Pourtant comme nous venons de le voir, la sortie de ce premier bloc est de dimension moindre que la séquence d'entrée, et ne porte plus de sens biologique en tant que tel. L'information transmise est un condensé de la séquence initiale.

Si l'on examine l'exemple ci-dessus, la séquence est de taille 14. En réalisant une convolution de noyau de taille 4, la représentation de sortie est de taille 11. Puis on applique un sous-échantillonnage avec une fenêtre de taille 3 donnant alors une représentation en sortie du premier bloc convolutif de taille 4. Au bloc convolutif suivant la convolution de cette représentation par un noyau de taille 4 donne lieu à une nouvelle représentation de taille 1, qui après pooling avec une fenêtre de taille 3 donne en sortie une représentation de taille 1.
Le raisonnement est le même à mesure que les couches se succèdent, les représentations diminuent de taille, et les neurones en aval d'une couche voient de plus en plus "large" dans les données d'entrée. il est à noter que les kernels de convolution, une fois leurs valeurs ajustées en fin d'entrainement, permettent alors d'extraire de la séquence en entrée les caractéristiques clés dans le choix de la classe en sortie du réseau. Par ailleurs, plus les couches seront profondes dans le réseau, plus les caractéristiques extraites seront complexes.
Première tentative
Dans cette première expérience, nous allons utiliser la descente de gradient stochastique, qui est un optimiseur de base.
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv1D(filters = 27, kernel_size = 4, activation = 'relu', padding = "valid", input_shape = (X_train.shape[1], X_train.shape[2])))
model.add(tf.keras.layers.MaxPool1D(pool_size=3, strides=None, padding='valid'))
model.add(tf.keras.layers.Conv1D(filters = 14, kernel_size = 4, activation = 'relu'))
model.add(tf.keras.layers.MaxPool1D(pool_size= 2, strides = None, padding = 'valid'))
model.add(tf.keras.layers.Conv1D(filters = 7, kernel_size = 4, activation = 'relu'))
model.add(tf.keras.layers.MaxPool1D(pool_size= 2, strides = None, padding = 'valid'))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(units = 1, activation = 'sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
# On definit un arret premature de l'entrainement en cas d'amelioration non notable apres plusieurs phases pour eviter le sur-entrainement
early_stop = keras.callbacks.EarlyStopping(monitor = 'val_accuracy', min_delta = 0.0005, patience=8,
restore_best_weights=True )
# On definit un monitoring les performances du modele et on lance l'entrainement
history = model.fit(X_train, y_train, batch_size = 128, validation_data=(X_test, y_test),
epochs=115)
# On plot les résultats de l'entrainement
plt.figure(figsize = (10,4))
plt.subplot(121)
plt.plot(history.epoch, history.history["loss"], 'g', label='Training loss')
plt.plot(history.epoch, history.history["val_loss"], 'b', label='Validation loss')
plt.title('Training loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(122)
plt.plot(history.epoch, history.history["accuracy"], 'r', label='Training accuracy')
plt.plot(history.epoch, history.history["val_accuracy"], 'orange', label='Validation accuracy')
plt.title('Training accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.savefig(work_folder + "base_model_deep_no_dropout_sgd.png")
plt.show()
Nous pouvons observer plusieurs choses sur nos courbes d'apprentissage. Premièrement, que ce soit en entrainement ou en validation, ni l'erreur, ni la performance n'atteignent de plateau. Il semblerait donc que malgré les 150 passes (epochs) d'apprentissage, l'optimum ne soit pas atteint.
NB : Une passe (ou epoch en anglais) correspond à une session d'entrainement du modèle. A la fin de la première epoch, l'ensemble des exemples d'apprentissage ont été vus une fois, à la fin de l'époque n l'ensemble de ces mêmes exemples ont été vus n fois par le réseau.
Par ailleurs, nous pouvons observer que les performances en validation, donc sur des exemples non-observés en entrainement, est moins bonne.
Notre modèle ne semble donc pas assez entraîné d'une part, et montre des difficultés à généraliser.

# Evaluation finale du modele
loss, acc = model.evaluate(X_validation, y_validation, verbose=2)
print("Untrained model, accuracy: {:5.2f}%".format(100 * acc))
71/71 - 0s - loss: 0.3394 - accuracy: 0.8575 - 404ms/epoch - 6ms/step Untrained model, accuracy: 85.75%)
Bien que les résultats ne soient pas parfait, le modèle présente 85.75% de justesse ce qui est déjà très bon. Voyons comment rendre notre modèle plus performant à l'aide d'un autre optimiseur.
L'optimiseur ADAM
Changeons l'optimiseur SGD pour un optimiseur de type ADAM. Cet optimiseur se base sur les fondements du SGD, mais utilise les moments de premier et second ordre du gradient de la fonction d'erreur. Cela permet à l'optimiseur d'avoir une "mémoire" de l'entrainement précédent, et donc de la force de la précédente modification des coefficient des noyaux de convolution.
Par ailleurs ce type d'optimiseur intègre un taux d'apprentissage adaptatif, qui va permettre de modifier fortement les coefficient des noyaux de convolution au début de l'entrainement, et moins fortement au fur et mesure des phases d'entrainement.
Ainsi notre modèle va apprendre en tenant compte de plus que l'entrainement précédent, et plus finement au fil des phases.
model_adam = tf.keras.Sequential()
model_adam.add(tf.keras.layers.Conv1D(filters = 27, kernel_size = 4, activation = 'relu', padding = "valid", input_shape = (X_train.shape[1], X_train.shape[2])))
model_adam.add(tf.keras.layers.MaxPool1D(pool_size=3, strides=None, padding='valid'))
model_adam.add(tf.keras.layers.Conv1D(filters = 14, kernel_size = 4, activation = 'relu'))
model_adam.add(tf.keras.layers.MaxPool1D(pool_size= 2, strides = None, padding = 'valid'))
model_adam.add(tf.keras.layers.Conv1D(filters = 7, kernel_size = 4, activation = 'relu'))
model_adam.add(tf.keras.layers.MaxPool1D(pool_size= 2, strides = None, padding = 'valid'))
model_adam.add(tf.keras.layers.Flatten())
model_adam.add(tf.keras.layers.Dense(units = 1, activation = 'sigmoid'))
model_adam.summary()
model_adam.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# On defini un arret premature de l'entrainement en cas d'amelioration non notable apres plusieurs phases pour eviter le sur-entrainement
early_stop = keras.callbacks.EarlyStopping(monitor = 'val_accuracy', min_delta = 0.0005, patience=8,
restore_best_weights=True )
# On defini un monitoring les performances du modele et on lance l'entrainement
history_adam = model_adam.fit(X_train, y_train, batch_size = 128, validation_data=(X_test, y_test),
epochs=115)
# On plot les résultats de l'entrainement
plt.figure(figsize = (10,4))
plt.subplot(121)
plt.plot(history_adam.epoch, history_adam.history["loss"], 'g', label='Training loss')
plt.plot(history_adam.epoch, history_adam.history["val_loss"], 'b', label='Validation loss')
plt.title('Training loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(122)
plt.plot(history_adam.epoch, history_adam.history["accuracy"], 'r', label='Training accuracy')
plt.plot(history_adam.epoch, history_adam.history["val_accuracy"], 'orange', label='Validation accuracy')
plt.title('Training accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.savefig(work_folder + "base_model_deep_no_dropout_adam.png")
plt.show()
L'optimiseur ADAM est reconnu pour converger plus rapidement (atteindre le minimum global de la fonction de coût), mais en revanche, avoir du mal à généraliser.

# Evaluation finale du modele
loss, acc = model_adam.evaluate(X_validation, y_validation, verbose=2)
print("Untrained model, accuracy: {:5.2f}%".format(100 * acc))
71/71 - 0s - loss: 0.3810 - accuracy: 0.8509 - 496ms/epoch - 7ms/step Untrained model, accuracy: 85.09%
Nous pouvons observer que les performances du modèle se maintiennent aux alentours de 85% de justesse. Néanmoins, les courbes d'erreur et de justesse semblent avoir un plateau. L'entrainement semble avoir été mené jusqu'au bout. Néanmoins nous observons d'une part que l'erreur est plus élevée (et respectivement la justesse moins élevée) lors de la validation que lors de l'entrainement, une fois de plus le modèle généralise moins bien sur des exemples inconnus. D'autre part, on observe une hausse de l'erreur en validation au delà de la 60ème passe. Ceci signe un sur-apprentissage du modèle, lequel semble très bien apprendre sur sa base d'apprentissage, si bien que lorsque des exemples nouveau se présentent, les performances chutent.
Voyons à présent comment remédier à ce problème de sur entrainement.
Le dropout
Afin de prévenir le sur apprentissage, une méthode consiste à accorder la possibilité au réseau de déconnecter temporairement certains de ses neurones. Ainsi après estimation de l'erreur, une portion des coefficients des noyaux de convolutions ne seront pas ajustés. C'est ce que l'on appelle le dropout.
Afin de paramétrer cette déconnexion, nous allons fixer le paramètre p compris entre 0 et 1, qui indique le pourcentage de neurones à déconnecter lors d'une phase d'ajustement des poids du réseau. Une valeur standard est 0.2. Ainsi durant une phase d'apprentissage donnée, 20% des neurones du réseau, choisis de manière aléatoire ne seront pas ajustés. Lors de la phase suivante, 20% de neurones seront à nouveau déconnectés, mais pas nécessairement les mêmes.
model_adam_dropout = tf.keras.Sequential()
model_adam_dropout.add(tf.keras.layers.Conv1D(filters = 27, kernel_size = 4, activation = 'relu', padding = "valid", input_shape = (X_train.shape[1], X_train.shape[2])))
model_adam_dropout.add(tf.keras.layers.MaxPool1D(pool_size=3, strides=None, padding='valid'))
model_adam_dropout.add(tf.keras.layers.Dropout(0.2))
model_adam_dropout.add(tf.keras.layers.Conv1D(filters = 14, kernel_size = 4, activation = 'relu'))
model_adam_dropout.add(tf.keras.layers.MaxPool1D(pool_size= 2, strides = None, padding = 'valid'))
model_adam_dropout.add(tf.keras.layers.Dropout(0.2))
model_adam_dropout.add(tf.keras.layers.Conv1D(filters = 7, kernel_size = 4, activation = 'relu'))
model_adam_dropout.add(tf.keras.layers.MaxPool1D(pool_size= 2, strides = None, padding = 'valid'))
model_adam_dropout.add(tf.keras.layers.Dropout(0.2))
model_adam_dropout.add(tf.keras.layers.Flatten())
model_adam_dropout.add(tf.keras.layers.Dense(units = 1, activation = 'sigmoid'))
model_adam_dropout.summary()
model_adam_dropout.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# On definit un arret premature de l'entrainement en cas d'amelioration non notable apres plusieurs phases pour eviter le sur-entrainement
early_stop = keras.callbacks.EarlyStopping(monitor = 'val_accuracy', min_delta = 0.0005, patience=8,
restore_best_weights=True )
# On definit un monitoring les performances du modele et on lance l'entrainement
history_adam_droupout = model_adam_dropout.fit(X_train, y_train, batch_size = 128, validation_data=(X_test, y_test),
epochs=115)
# On plot les résultats de l'entrainement
plt.figure(figsize = (10,4))
plt.subplot(121)
plt.plot(history_adam_droupout.epoch, history_adam_droupout.history["loss"], 'g', label='Training loss')
plt.plot(history_adam_droupout.epoch, history_adam_droupout.history["val_loss"], 'b', label='Validation loss')
plt.title('Training loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(122)
plt.plot(history_adam_droupout.epoch, history_adam_droupout.history["accuracy"], 'r', label='Training accuracy')
plt.plot(history_adam_droupout.epoch, history_adam_droupout.history["val_accuracy"], 'orange', label='Validation accuracy')
plt.title('Training accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.savefig(work_folder + "base_model_deep_dropout_adam.png")
plt.show()
A noter que lorsque le modèle est entraîné et rend des prédiction, l'ensemble des neurones sont connectés. Le dropout ne concerne que l'apprentissage.

# Evaluation finale du modele
loss, acc = model_adam_dropout.evaluate(X_validation, y_validation, verbose=2)
print("Untrained model, accuracy: {:5.2f}%".format(100 * acc))
71/71 - 0s - loss: 0.2720 - accuracy: 0.8819 - 365ms/epoch - 5ms/step Untrained model, accuracy: 88.19%
Nous observons comme dans l'exemple précédent, l'atteinte d'un plateau au niveau des courbes d'erreur et de justesse, autant pour l'entrainement que la validation.
D'autre part, nous n'observons plus de divergence notable entre entrainement et validation (en erreur et en justesse) au long de l'entrainement. Nous semblons donc avoir mené à bien l'entrainement du modèle sans provoquer de sur-apprentissage.
Il est à noter que la dernière valeur de justesse est plus basse avec l'utilisation du dropout (environ 85%) que lors de la précédente expérience (environ 90%). Pourtant lors de l'évaluation du modèle, les performances passent de 85% pour le modèle précédent à 88% pour ce modèle.
Les tentatives de rendre les modèles plus généralisables s'accompagnent parfois de pertes de performances. Toutefois nous semblons ici avoir établi un modèle aux performances honorables.
Conclusion
Ainsi s'achève une première expérience d'application de deep-learning à des problématiques de bioinformatique. Nous avons construit un modèle permettant de classer des séquences de 301 nucléotides entre séquences promotrices et non-promotrices.
Nous avons pu voir que de nombreux hyper-paramètres entraient en ligne de compte lors de la construction et lors de l'entrainement du modèle, afin de le rendre plus robuste aux nouveaux exemples, et de l’entraîner dans des délais raisonnables.
Il est à garder à l'esprit que cette architecture de réseau n'est pas la seule permettant de répondre à cette question, ni même la meilleure. De nombreuses possibilités sont offertes afin de parfaire ce modèle, qu'il s'agisse de paramétrisation ou d'architecture.
L'ensemble du code est disponible sur ce repo : https://github.com/bioinfo-fr/data_ia/blob/main/DNA_CNN_promoters.ipynb
Pour aller plus loin avec les réseaux convolutifs
Quelques ressources sur les CNN : https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
Un grand merci à nos relecteurs pour cet article : Léopold, Samuel, Yoann et Guillaume !
Laisser un commentaire