


Git est un logiciel de contrôle de versions de fichiers. Il est distribué sous licence GNU GPLv2 et est disponible sur les principaux systèmes d'exploitation.
Cet article est le premier d'une série de deux. Nous allons voir ici (1) à quoi sert le contrôle de versions, (2) comment configurer git et (3) les bases de son utilisation.
Dans l'article suivant, nous verrons comment cloner un projet (par exemple pour travailler à plusieurs ou pour faire des sauvegardes) et comment synchroniser les différentes copies.
Contexte :
Pourquoi faire ?
Logiciels de contrôle de version
Il existe par ailleurs une quantité impressionnante de didacticiels sur git. Souvent en anglais, mais promis, nous allons faire un effort ici. Pour un usage efficace d'un tutoriel, il est généralement conseillé de faire ce que personne ne fait jamais : reproduire les commandes et autres manipulations chez vous. (présence d'un adulte non nécessaire) Et, n'oubliez jamais : un gestionnaire de versions se souvient de tout. NO EXCEPTION
Configurer git une bonne fois pour toutes
Sans git
Avec git
.
# Vous pouvez utiliser les paquets de votre distribution, ou à défaut télécharger git depuis http://git-scm.com.
# Ici on se simplifie la vie et on prend la première option.
# Adaptez selon votre distribution.
sudo apt-get install git # debian, ubuntu et consorts
sudo pacman -S git # archlinux
# pour les autres, soit vous savez, soit vous êtes sur mac ou windows…
git config --global user.name "Gérard Menvuça"
git config --global user.email "super.gege@wanadold.fr"Pourquoi ?
|
1 |
~/.gitconfig |
que les valeurs sont enregistrées ici… C'est en fait ici que git cherchera si, dans le projet dans lequel vous travaillez, aucune de ces informations n'est renseignée. Pour les trois de devant qui suivent : oui, cela permet d'avoir plusieurs identités.
Le cas Windows/OSX
Git est un programme suffisamment démocratisé pour se retrouver partout. Sous tout OS Unix-like (donc OSX aussi), git est utilisable dans la console, fût-elle bien cachée, et installable d'une manière ou d'une autre.
Pour Windows, on nous souffle en coulisse que Powershell gère l'affaire avec la même interface que les autres. Youpi !
Git pour remplir 2 Gb de RAM
Pour les plus allergiques à la ligne de commande, ou pour ceux qui n'intègrent pas cet outil à leur workflow, il existe une quantité importante d'interfaces graphiques qui encapsulent les commandes détaillées dans ce tuto.
Elles nécessitent toujours une compréhension de ce qu'est git et de ce qu'il fait (du moins cela ne peut que aider), ne vous attendez donc pas à vous économiser la totalité de ce tutoriel en vous contentant d'un clicodrôme (d'autant que certaines fonctionnalités avancées dont vous pourriez un jour avoir besoin pourraient nécessiter l'intervention en ligne de commande).
Créer un projet vide
Sans git
Un
|
1 |
mkdir |
et pouf, c'est fini !
Avec git
Un "
|
1 |
git init |
" et pouf, c'est fini aussi. On en profitera pour voir également "
|
1 |
git status |
".
git init
Cette commande crée un dépôt (aussi appelé repository), c'est à dire un répertoire que git surveillera et gèrera, pendant que vous y ajouterez ou modifierez vos fichiers. Dans le jargon git, cela se traduit par la création d'un dossier caché nommé "
|
1 |
.git |
", à l'endroit précis où vous vous trouvez quand vous lancez "
|
1 |
git init |
". Ce répertoire
|
1 |
.git |
contiendra toutes les informations sur le dépôt, ainsi que vos configurations locales. Certaines des (très) nombreuses options seront abordées dans cet article. Les autres, moins importantes, sont facilement trouvables sur le net, et, pour vos premières utilisations, il y a peu de chances que vous en ayez besoin :
$ mkdir /some/path/to/your/project # création du répertoire
$ cd /some/path/to/your/project # on va dedans
$ ls -a # le répertoire est bien vide
. ..
$ git init # bon, ben, créons un dépôt git vide initialisé dans /some/path/to/your/project/.git/
$ ls -a # la commande "git init" crée un répertoire caché ".git"
. .. .git
$ ls .git # on jette un oeil dans le répertoire
branches config description HEAD hooks info objects refsComme vous pouvez le constater, il y a déjà plein de trucs dans le
|
1 |
.git |
alors qu'on n'a encore rien écrit… Rien d'anormal ; c'est comme quand vous venez d'installer un système : il y a déjà plein de bazar dans des répertoires inutiles tels que lib, bin ou dev, users, programs,… mais si vous tripotez trop à ce qui s'y trouve sans savoir ce que vous faites, eh bien… vous aurez quelques problèmes avec votre install. Git c'est pareil. Laissez-le gérer ses fichiers, il est meilleur que vous à ce niveau (pour les vôtres aussi d'ailleurs). Néanmoins, vous serez peut-être amenés à modifier un peu les fichiers "
|
1 |
.git/config |
" et "
|
1 |
.git/description |
" selon ce que vous voudrez, plus tard, quand cet article n'aura plus de secrets pour vous.
git status
Cette commande ne modifie rien, elle ne fait que parler. Et pourtant, vous l'adorerez : elle renseigne sur l'état actuel du dépôt. Voyez plutôt :
$ git status
On branch master
Initial commit
nothing to commit (create/copy files and use "git add" to track)Ici, git nous indique clairement qu'on devrait se mettre au boulot. Il dit même comment (vous verrez, git est très malin à ce petit jeu), ce qui spoile un peu la prochaine partie de cet article.
Plus tard, cette commande nous resservira. C'est l'occasion de revenir sur le répertoire caché "
|
1 |
.git |
" créé lors du "
|
1 |
git init |
" : lorsque vous faite une commande git, par exemple "
|
1 |
git status |
", git va chercher le premier répertoire "
|
1 |
.git |
" qu'il trouvera en partant du répertoire courant puis en remontant successivement. De fait, lorsque vous serez la tête dans votre projet avec votre
|
1 |
pwd |
quelque part dans la hiérarchie, git trouvera seul le dépôt, et trouvera les infos nécessaires dans le "
|
1 |
.git |
". Par contre, lorsque vous n'êtes pas dans un dépôt et faites "
|
1 |
git status |
", git va vous sermoner. La preuve : git est remonté jusqu'à la racine système sans trouver le moindre "
|
1 |
.git |
".
Principes de base (pour travailler seul(e))
Sans git
Codez.
Si vous supprimez un fichier par erreur : perdez votre travail et priez pour
|
1 |
foremost |
sans passer par la case départ. Si vous voulez faire des sauvegardes de version, faites des dumps de dossiers avec des noms que vous ne comprendrez plus dans 2h, et que de toute façon vous ne réutiliserez jamais, sauf la semaine prochaine après le problème de sauvegarde ; mais de toute façon vu que vous aviez tout refactorisé, autant tout reprendre de zéro : effacez les dossiers de sauvegarde faits à la main, allez demander de l'aide sur stackoverflow. Expliquez à votre boss que vous n'auriez pas une semaine de retard si
|
1 |
mv |
et
|
1 |
rm |
n'était pas aussi proches syntaxiquement, apprenez l'existance d'un truc qui s'appelle gestionnaire de versions, prenez peur en lisant la page wikipédia, découvrez cet article. Expirez profondément, vous êtes sur la bonne voie et tout va déjà mieux.
Avec git
git status
Après la création du dépôt, "
|
1 |
git status |
" vous disait que tout allait bien, et que la prochaine chose à faire est de créer des fichiers, puis d'utiliser "
|
1 |
git add |
".
|
1 |
firstFile.txt |
" et voir ce qui se passe.
$ vi firstFile.txt
$ cat firstFile.txt
This is the first line of my first file...
... and this is the second line
$Ici, le fichier est créé à l'aide de
|
1 |
vi |
, mais, évidemment, vous pouvez utiliser n'importe quoi : git se contente de comparer des fichier. Vous pouvez copier-coller un fichier dans votre dépôt ou en créer un en modifiant votre disque dur avec un aimant ou un cure-dent, ce sera pareil : git n'a rien à voir avec un éditeur de fichier, et se contente de comparer des fichiers quand vous le lui demandez. (il existe en réalité une exception, lors de la gestion des conflits, qui sera vu plus tard)
Maintenant que nous avons créé le fichier, voici la réaction de git :
$ git status
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
firstFile.txt
nothing added to commit but untracked files present (use "git add" to track)
git add
Dans l'exemple précédent, on voit que créer le fichier
|
1 |
firstFile.txt |
dans le dépôt ne suffit pas pour que git le prenne en charge automatiquement, et qu'il faut pour cela faire un "
|
1 |
git add |
".
$ git add firstFile.txt
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: firstFile.txt
$Cela peut sembler inutilement compliqué et malcommode, mais c'est nécessaire afin d'indiquer quels sont les fichiers intéressants. On verra dans la section sur
|
1 |
.gitignore |
un peu plus loin comment traiter les fichiers pas intéressants.
Après avoir explicitement inclus
|
1 |
firstFile.txt |
dans la liste des fichiers que git doit gérer, le dernier "
|
1 |
git status |
" indique que le fichier est bien pris en compte. À ce stade, git sait qu'il doit surveiller ce fichier et il en a pris une empreinte de la version courante (un snapshot dans la documentation en anglais), qu'il stocke dans une zone temporaire appelée l'index. Si maintenant on modifie le fichier
|
1 |
firstFile.txt |
, git sait qu'il doit le surveiller et indique que le snapshot qu'il a pris lors du "
|
1 |
git add |
" n'est plus à jour. Il faut donc faire un nouveau "
|
1 |
git add |
" pour réactualiser le snapshot. L'exemple suivant illustre ce principe : le premier "
|
1 |
git status |
" reprend l'étape précédente et indique que tout va bien ; on modifie ensuite le fichier et le "
|
1 |
git status |
" qui suit indique que git dispose bien d'un snapshot dans sa zone temporaire (c'est la ligne "
|
1 |
new file : firstFile.txt |
" qui est similaire à ce qu'on avait avant), mais que ce snapshot n'est plus à jour car le fichier a été modifié depuis (ce sont les lignes à partir de "
|
1 |
Changes not staged for commit : |
"). On fait de nouveau un "
|
1 |
git add firstFile.txt |
" pour mettre à jour le snapshot et le troisième git status montre que tout va bien à nouveau et que les changements sont prêts pour un
|
1 |
commit |
(cf. section suivante).
$ cat firstFile.txt
This is the first line of my first file...
... and this is the second line
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: firstFile.txt
$ vi firstFile.txt
$ cat firstFile.txt
This is the first line of my first file...
... and this is the second line
Now we add another line
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: firstFile.txt
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: firstFile.txt
$ git add firstFile.txt
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: firstFile.txtDe même, si on crée de nouveaux fichiers (par exemple un readme et un fichier de licence) ou de nouveaux répertoires, il faut les ajouter avec "
|
1 |
git add |
". Il est possible d'ajouter plusieurs fichiers avec un seul "
|
1 |
git add |
". L'ajout d'un répertoire entraine l'ajout automatique de tous les fichiers qu'il contient ; les répertoires vides sont ignorés.
$ ls
firstFile.txt
$ vi README.txt
$ vi licence.txt
$ mkdir doc
$ vi doc/documentation.txt
$ vi doc/otherDocumentation.txt
$ find . -name .git -a -type d -prune -o -print
.
./README.txt
./doc
./doc/documentation.txt
./doc/otherDocumentation.txt
./firstFile.txt
./licence.txt
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: firstFile.txt
Untracked files:
(use "git add <file>..." to include in what will be committed)
README.txt
doc/
licence.txt
$ git add README.txt licence.txt doc
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: README.txt
new file: doc/documentation.txt
new file: doc/otherDocumentation.txt
new file: firstFile.txt
new file: licence.txtÀ propos de la discrimination des dossiers vides, car, diantre ! Cela peut être ennuyeux pour les dossiers de logs, et il ne s'agit pas d'un bug de fonctionnement :
dans la vraie vie réelle de l'internet, il existe plusieurs moyens de garder un dossier vide (comme ici ou là), et c'est a vous de choisir votre solution préférée (3615 ma life de lucas : j'ai une préférence pour le bricolage de .gitignore, puisqu'il permet de spécifier des patterns de fichier à ignorer, typiquement les fichiers avec une extension log, swp,…). L'usage du gitignore sera détaillé plus loin.
git commit (+ git status)
À ce stade, git surveille bien les fichiers et en prend des snapshots, mais l'index où ils sont stockés n'est qu'une zone temporaire. Lorsque les fichiers sont à jour, le "
|
1 |
git status |
" indique qu'ils sont maintenant prêts à être archivés de façon définitive avec un "
|
1 |
git commit |
". Typiquement, on travaille sur certains fichiers en faisant des modifications (éventuellement plusieurs, comme nous l'avons fait aux figures précédentes) jusqu'à réussir à ajouter une nouvelle fonctionnalité ou jusqu'à en avoir débuggué une. Le
|
1 |
git commit |
permet alors de dire "Voilà, cette version des fichiers correspond à telle action". Cette version devient la nouvelle version à jour qui peut être partagée. Remarquez que le seul changement de version "officielle" se fait d'un commit à l'autre, sans que personne ne voit la longue série de modifications plus ou moins habiles qui figurait dans les "
|
1 |
git add |
" et qui vous a permis d'y parvenir.
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: README.txt
new file: doc/documentation.txt
new file: doc/otherDocumentation.txt
new file: firstFile.txt
new file: licence.txt
$ git commit -m "First commit"
[master (root-commit) e26b158] First commit
5 files changed, 10 insertions(+)
create mode 100644 README.txt
create mode 100644 doc/documentation.txt
create mode 100644 doc/otherDocumentation.txt
create mode 100644 firstFile.txt
create mode 100644 licence.txt
$ git status
On branch master
nothing to commit, working directory cleanLe paramètre
|
1 |
-m |
permet d'indiquer un message décrivant (brièvement) la fonctionnalité que vous avez ajoutée ou celle que vous avez améliorée ou corrigée. Il faut que ce message soit concis et informatif (bon, ce n'est pas facile sur le premier
|
1 |
commit |
). Si vous pensez qu'il faut donner des détails, commencez quand même par une phrase brève, laissez une ligne blanche, puis racontez ce que vous voulez.
Si vous ne donnez pas l'option m et le message de commit, git va appeler votre éditeur de texte par défaut (souvent nano si vous n'avez rien changé, définit par la variable d'environnement $EDITOR), ou un autre si vous avez utilisé la commande
|
1 |
"git config --global core.editor "vim"" |
ou équivalent. Une fois démarré, l'éditeur de texte vous laissera écrire le message de commit.
Un parallèle avec l'industrie du bâtiment est possible : imaginez un commit comme une brique utilisée pour construire un mur. C'est l'ensemble des briques posées les unes sur les autres qui rendent le projet final. Plus tard, nous verrons qu'il est possible de cloner un mur en construction pour apposer ses propres briques, et de proposer ensuite une fusion des murs : le début du travail collaboratif. Pour récapituler, il faut donc faire une combinaison d'une suite de "
|
1 |
git add |
" pour ajouter les fichiers pertinents à l'index, et "
|
1 |
git commit |
" pour valider les changements des fichiers de l'index. Lorsque vous commencez à savoir ce que vous faites, un "
|
1 |
git commit -a -m |
" combine les deux commandes précédentes en ajoutant les fichiers qui ont changé (mais pas les nouveaux) à l'index et en les validant. Il est donc aisé de commiter plusieurs fichiers simultanément. Néanmoins, cela va à l'encontre de la philosophie de git : un commit devrait toujours être une modification atomique, pas une pleine brouette de code désorganisée et obèse. Une exception notable est cependant lorsque vous créez un dépôt pour un projet, comme Linus avant tous, le premier
|
1 |
commit |
(nommé souvent "
|
1 |
initial commit |
") est généralement un gros dump de ce qui a été fait auparavant. Par exemple, cela permet simplement de suivre avec un échantillonnage élevé l'évolution d'un projet, et donc de contrôler facilement les ajouts de fonctionnalités, les versions,… Exactement ce pourquoi git existe. Et en plus c'est mieux pour faire de jolis graphiques !
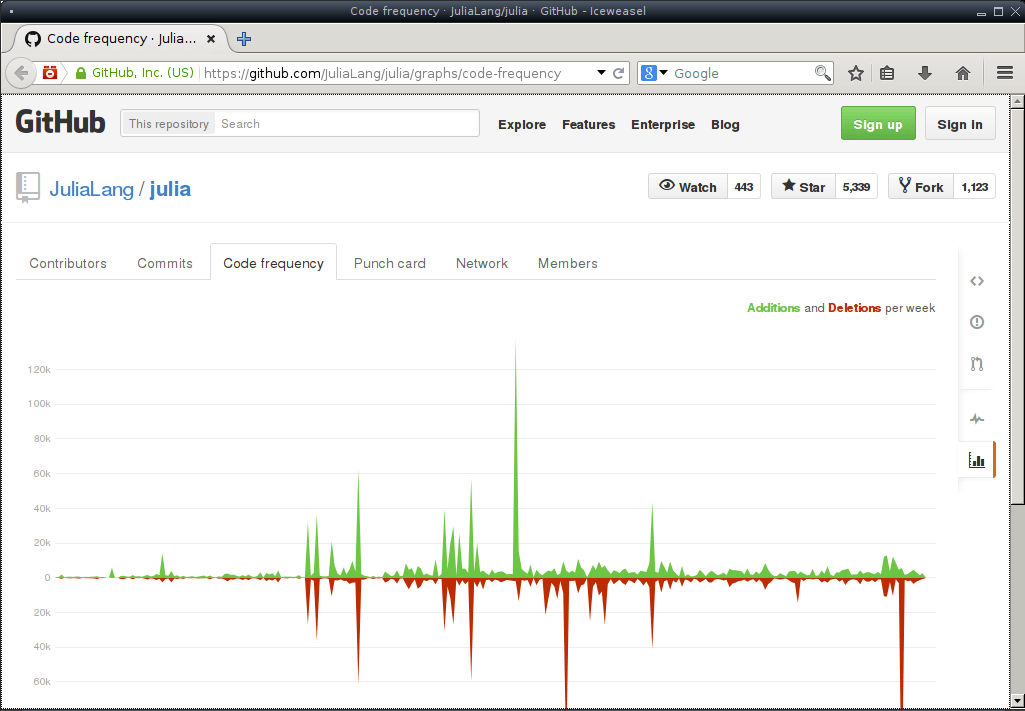
Donc : préférez des
|
1 |
commit |
s atomiques et simples, touchant le minimum de fichiers à chaque fois, avec un message de
|
1 |
commit |
qui répond au pourquoi, et non au comment dont la réponse est déjà dans le
|
1 |
commit |
. Le dépôt du langage Julia présenté dans un autre article est un bon exemple : des milliers de
|
1 |
commit |
s, et même les tous premiers sont atomiques :
$ git clone https://github.com/JuliaLang/julia
$ cd julia
$ git log --reverse # afficher les commits du plus ancien au plus récentgit log pour suivre l'historique des commit
La commande "
|
1 |
git log |
" vous permet de lister l'auteur, la date et la description succinte (celle qui figurait après le -m) des "
|
1 |
git commit |
" successifs.
La commande git log mériterait un tuto à elle toute seule. Dans un premier temps, la connaitre et l'utiliser sans arguments suffit largement.
Disons que les trois lignes précédentes seront votre premier TP, si par malheur vous ne reproduisez pas le tuto à la lecture.
git diff
Au cours du cycle typique "modification de fichier(s) <->
|
1 |
git add |
<->
|
1 |
git commit |
", git permet plusieurs points de contrôle (le "
|
1 |
git add |
" met à jour l'index temporaire et le "
|
1 |
git commit |
" met à jour le dépôt à partir de l'index) et on peut avoir besoin d'analyser ce qui a changé de l'un à l'autre grâce à la commande "
|
1 |
git diff |
".
- Par défaut, "
" permet de comparer la version courante du fichier avec la dernière version prise en compte par l'index (donc ce qui a changé dans la version actuelle du fichier depuis le dernier "1git diff")1git add
- Par contre, "
" permet de comparer la dernière version prise en compte par l'index avec l'état lors du dernier commit (donc ce qui va être modifié lors du prochain1git diff --cached)1commit
Il faut bien remarquer qu'on ne compare jamais la version actuelle du fichier avec celle du dernier
|
1 |
commit |
, mais ce n'est pas très grave puisqu'il faut de toutes façons passer par un "
|
1 |
git add |
" entre les deux. Pour bien détailler toutes ces étapes, on va faire une première modification dans un fichier, faire un "
|
1 |
git add |
" pour mettre à jour l'index, puis faire une seconde modification. On voit que le "
|
1 |
git diff |
" montre bien la version courante du fichier, mais ne met en valeur que la seconde modification, alors que "
|
1 |
git diff --cached |
" ne montre et ne met en valeur que la première modification et ignore la seconde. Si ça vous semble normal, c'est que vous avez bien assimilé le principe de git ; sinon relisez les sections sur "
|
1 |
git add |
" et "
|
1 |
git commit |
".
$ cat firstFile.txt
This is the first line of my first file...
... and this is the second line
Now we add another line
$ git status
On branch master
nothing to commit, working directory clean
$ echo "Adding a fourth line" >> firstFile.txt
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: firstFile.txt
no changes added to commit (use "git add" and/or "git commit -a")
$ git diff
diff --git a/firstFile.txt b/firstFile.txt
index 9a4e002..d5078b7 100644
--- a/firstFile.txt
+++ b/firstFile.txt
@@ -3,3 +3,4 @@ This is the first line of my first file...
Now we add another line
+Adding a fourth line
$ git add firstFile.txt
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: firstFile.txt
$ git diff
$ git diff --cached
diff --git a/firstFile.txt b/firstFile.txt
index 9a4e002..d5078b7 100644
--- a/firstFile.txt
+++ b/firstFile.txt
@@ -3,3 +3,4 @@ This is the first line of my first file...
Now we add another line
+Adding a fourth line
$ echo "Adding a fifth line" >> firstFile.txt
$ git diff
diff --git a/firstFile.txt b/firstFile.txt
index d5078b7..ba75664 100644
--- a/firstFile.txt
+++ b/firstFile.txt
@@ -4,3 +4,4 @@ Now we add another line
Adding a fourth line
+Adding a fifth line
$ git diff --cached
diff --git a/firstFile.txt b/firstFile.txt
index 9a4e002..d5078b7 100644
--- a/firstFile.txt
+++ b/firstFile.txt
@@ -3,3 +3,4 @@ This is the first line of my first file...
Now we add another line
+Adding a fourth line
$ git commit -m "this commit only adds the fourth line; the fifth is ignored as it is not yet in the index"
[master 61b5f1d] this commit only adds the fourth line; the fifth is ignored as it is not yet in the index
1 file changed, 1 insertion(+)
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: firstFile.txt
no changes added to commit (use "git add" and/or "git commit -a")
$ git diff
diff --git a/firstFile.txt b/firstFile.txt
index d5078b7..ba75664 100644
--- a/firstFile.txt
+++ b/firstFile.txt
@@ -4,3 +4,4 @@ Now we add another line
Adding a fourth line
+Adding a fifth line
$ git diff --cached
$ Le dernier "
|
1 |
git status |
" indique que
|
1 |
firstFile.txt |
a été modifié depuis le dernier snapshot (ben oui, on vient d'y ajouter successivement deux lignes pour illustrer "
|
1 |
git diff |
" et "
|
1 |
git diff --cached |
"). On en profite pour mettre de l'ordre tout en récapitulant avec un "
|
1 |
git add |
" pour mettre le snapshot à jour, puis un "
|
1 |
git commit |
".
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: firstFile.txt
no changes added to commit (use "git add" and/or "git commit -a")
$ git add firstFile.txt
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: firstFile.txt
$ git commit -m "added two more lines to explain how git diff works"
[master fcae267] added two more lines to explain how git diff works
1 file changed, 1 insertion(+)
$ git status
On branch master
nothing to commit, working directory clean
$gitignore
Dans un projet, il y a des fichiers ou des répertoires qu'il n'est pas utile d'archiver ou de partager comme par exemple des fichiers intermédiaires de compilation, des fichiers de log, les fichiers
|
1 |
.bak |
générés par certains éditeurs… Tant qu'on ne les ajoute pas grâce à un "
|
1 |
git add |
" ce n'est pas bien grave, mais ils ont quand même l'inconvénient de polluer les "
|
1 |
git status |
". De plus, on a vu précédemment que lors d'un "
|
1 |
git add |
" sur un répertoire, git ajoute à l'index tous les fichiers du répertoire, y compris les fichiers indésirables.
En plus des fichiers inutiles, il est également bon d'éviter d'ajouter des fichiers binaires ou des fichiers compressés à un projet si ceux-ci peuvent être ammenés à changer. En effet, git est bien adapté aux fichiers textes mais pas trop aux autres types de fichiers (c'est logique, souvenez-vous du
|
1 |
git diff |
de la section précédente). Normalement, à chaque modification, git ne stocke que ce qui a changé depuis la dernière version. Dans le cas des fichiers binaires, il est donc obligé de stocker la version complète du fichier à chaque modification, ce qui conduit rapidement à une augmentation importante de la taille du dépôt.
Il est possible d'indiquer à git qu'il doit ignorer certains fichiers (en donnant leur nom), ou certains types de fichiers (à l'aide d'expressions régulières). Pour cela, créez un fichier nommé "
|
1 |
.gitignore |
" à la racine du projet (dans le répertoire où il y a aussi le répertoire "
|
1 |
.git |
" généré lors du "
|
1 |
git init |
"). Dans le fichier "
|
1 |
.gitignore |
", mettez un nom de fichier ou une expression régulière par ligne.
$ git status
On branch master<br>nothing to commit, working directory clean
$ touch firstFile.txt.bak
$ mkdir log
$ touch log/example.log
$ touch log/example.log.gz
$ git status
On branch master<br>Untracked files:
(use "git add <file>..." to include in what will be committed)
firstFile.txt.bak
log/
nothing added to commit but untracked files present (use "git add" to track)
$ vi .gitignore
$ cat .gitignore
*.bak
log/
$ On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)
$ ls -a
. .. doc firstFile.txt firstFile.txt.bak .git .gitignore licence.txt log README.txt
Le dernier "
|
1 |
git status |
" indique deux choses :
- les fichiers se terminant en "
" et le répertoire "1.bak" existent bien mais sont ignorés par git conformément au contenu du fichier "1log"1.gitignore
- le fichier "
" est traité par git comme un fichier normal (on va développer ce point dans le prochain paragraphe) et il nous faut donc faire un "1.gitignore" afin que git l'ajoute au dépôt, surveille ses modifications et le partage éventuellement avec d'autres utilisateurs.1git add
$ git add .gitignore
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: .gitignore
$ git commit -m "added a .gitignore file to ignore backup files and the log directory"
[master 7deabd7] added a .gitignore file to ignore backup files and the log directory
1 file changed, 2 insertions(+)
create mode 100644 .gitignore
$ git status
On branch master
nothing to commit, working directory clean<
$Il faut bien comprendre que le contenu du fichier "
|
1 |
.gitignore |
" est lu par git et qu'il indique les fichiers dont git ne tient pas compte lors de la mise à jour de l'index. Si vous avez l'esprit taquin, vous pouvez évidemment mentionner "
|
1 |
.gitignore |
" dans votre "
|
1 |
.gitignore |
". Git continuera bien à en lire le contenu, mais n'ajoutera simplement pas votre "
|
1 |
.gitignore |
" à l'index.
Ce n'est sans doute pas une bonne idée si plusieurs personnes collaborent au projet. En effet, vos partenaires ne récupèreront donc pas votre "
|
1 |
.gitignore |
" avec les autres fichiers du projet. Ils risquent alors d'ajouter des fichiers indésirables lorsqu'ils feront un "
|
1 |
git commit |
" (mais grâce à la nature décentralisée de git, vous aurez quand même le loisir de rejeter leur
|
1 |
commit |
, il vous faudra juste refaire le ménage à la main).
|
1 |
.gitignore |
d'un projet à l'autre, donc c'est un bon investissement. Il existe également des générateurs de
|
1 |
.gitignore |
< Une application très parlante du gitignore dans tout projet Python est d'ignorer l'ensemble des fichiers issus de la compilation :
*.pyc
__pycache__/
On peut également utiliser le gitignore pour conserver un dossier vide, comme expliqué dans la partie dédiée à git add, tout en évitant de tracker l'ensemble des fichiers de logs.
Note importante : avoir un gitignore n'est pas obligatoire. Un gitignore n'affecte que le dossier où il se trouve ainsi que ses sous-dossiers. Vous pouvez avoir plusieurs gitignore.
Conclusion
Les outils de gestion de versions comme git sont bien plus simples à utiliser qu'on ne le pense (du moins pour une utilisation de base).
Nous avons vu comment créer un dépôt, sélectionner les fichiers et les répertoires que l'on veut prendre en compte et enregistrer leurs versions successives. Dans le prochain article, nous verrons comment utiliser git dans un contexte collaboratif, détecter et résoudre les conflits que cela peut entrainer, créer des branches et indiquer les étapes qui correspondent à des versions.
L'excellent site first aid git recense les questions les plus fréquentes sur git (et leurs réponses)
Remerciements
Merci à Hautbit, NiGoPol et Slybzh pour les commentaires et discussions lors de l'édition de cet article.
À propos de cet article
Cet article et le suivant ont étés adaptés à partir d'un cours donné par Lucas Bourneuf.
Il a été rédigé par Lucas Bourneuf et Olivier Dameron.
Laisser un commentaire