

Introduction
Cette plante est-elle comestible ? Cet animal est-il dangereux ? Classer des choses similaires dans une même catégorie et des choses dissimilaires dans différentes catégories est une idée intuitive que les enfants pratiquent dès le plus jeune âge. On utilise ainsi le même mot, « une chaise » par exemple, pour désigner une très grande variété d’objets possédant toutefois un certain nombre de propriétés communes : objet artificiel, permettant de s’asseoir, conçu pour une seule personne, possédant quatre pieds, un dossier, suffisamment étroit pour s’encastrer sous une table.
Mais ces catégories à la fois subjectives et floues des langues naturelles sont généralement inadéquates pour la recherche scientifique. Cette dernière nécessite en effet souvent de travailler sur des catégories objectives, rigoureuses. Il est donc nécessaire de définir des procédures de classifications claires et reproductibles, autrement dit un algorithme de clustering dans la langue d’Ada Lovelace. On attend d’une bonne classification scientifique qu’elle permette de stocker et de retrouver de nombreuses données de manière efficace, qu’elle soit prédictive dans le sens où si deux objets appartiennent à une même classe alors on pourra prédire certaines propriétés de l’un grâce à nos connaissances des propriétés de l’autre, et enfin qu’elle mette en évidence des motifs (on parle aussi de patterns) qui n’étaient pas flagrants et qui sont précieux pour dégager les phénomènes naturels à l’origine de ces données (ou processes).
Les algorithmes de clustering peuvent ainsi être appliqués dans de nombreux champs de la biologie : phylogénétique, écologie, génétique, psychologie, neurologie, médecine, épidémiologie, etc. Ils s’appliquent aussi bien sûr dans de nombreuses autres disciplines comme l’économie, le marketing, l’intelligence artificielle… La classification des données est une compétence des data science en général.
Dans une vidéo récente sur ma chaine Évoluscope, j’introduisais l’algorithme UPGMA (Unweighted Pair Group Method with Arithmetic mean), un outil à la fois simple et populaire de classification hiérarchique, en expliquant son fonctionnement :
Dans cet article complémentaire je souhaite donner une vue d’ensemble (sans prétendre à l’exhaustivité) de la diversité des algorithmes de clustering qu’on peut être amené à utiliser (avec des packages en R ou en Python), voire à coder, en tant que bioinformaticien ou data scientist en général. Nous allons donc passer en revue 6 propriétés binaires de ces divers algorithmes. J’utiliserai les termes de classification et de clustering comme synonymes. J'utiliserai de même les termes de classe, groupe et cluster de manière interchangeable.
1. Clustering supervisé vs non supervisé
On parle de clustering supervisé lorsque les groupes dans lesquels les objets doivent être classés sont connus à l’avance. On peut définir un groupe par une liste de propriétés, un seuil maximal de dissimilarité par rapport à un centroïde, ou bien par des exemples d’éléments appartenant à ce groupe. Dans ce dernier cas on dit que ces exemples sont étiquetés (labelled). L’objectif n’est donc pas de construire des groupes, mais de classer correctement des éléments nouveaux. C’est typiquement ce qu’il se passe lorsqu’on entraine des réseaux de neurones à reconnaitre des photos de chats et de chiens, puis qu’on leur présente de nouvelles photos qui n’étaient pas présentes dans les données d’entrainement. On suit aussi une démarche de clustering supervisé lorsqu’on suit un arbre de décision pour classer une situation nouvelle ou lorsqu’on se sert d’une clé de détermination pour identifier l’espèce à laquelle appartient un spécimen.
À l’inverse dans le clustering non supervisé on ne possède aucune information préalable sur les groupes, l’algorithme doit les découvrir. On construit alors les groupes à l’aide des propriétés des objets, codées numériquement, et/ou d’indices globaux nous renseignant les similarités ou dissimilarités entre les objets et entre les groupes.
2. Clustering hiérarchique vs non hiérarchique
Comme discuté dans la vidéo sur l’UPGMA, les algorithmes de clustering hiérarchique organisent les objets en une structure arborescente où chaque nœud représente un groupe. On appelle cette structure arborescente un dendrogramme. Elle est la représentation graphique d’une hiérarchie dans le sens mathématique du terme, c’est-à-dire un ensemble 
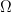
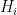




Les algorithmes de clustering non hiérarchique produisent au contraire une partition plate des objets, il n’y a pas alors de niveaux imbriqués les uns les dans les autres (si on exclut les singletons et la racine).

On retrouve dans cette catégorie un certain nombre d’algorithmes très populaires comme le k-means. Sans rentrer dans les détails, cet algorithme cherche à partitionner les objets dans k clusters en minimisant les dissimilarités moyennes entre les objets au sein de ces clusters. Un inconvénient majeur de cet algorithme est que l’utilisateur doit décider à l’avance de la valeur de k, le nombre de clusters.
Des alternatives existent, comme DBSCAN, également très populaire. Cet algorithme produit une partition des objets en classant dans un même cluster tous les voisins d’un point A ayant une dissimilarité maximale r par rapport à A s’il y au moins n voisins. DBSCAN n’a donc pas besoin qu’on décide à l’avance du nombre de clusters, mais il faut fixer deux autres paramètres : le rayon r et le nombre minimal de voisins n. De plus, certains objets resteront non classés si leur voisinage n’est pas assez dense ou qu’ils ne font pas partie du voisinage dense d’un autre objet.
On doit aussi considérer comme non hiérarchique tout algorithme produisant une structure arborescente non enracinée. Chaque branche représente alors une bipartition de l’ensemble des objets à classer. L’algorithme du Neighbor-Joining (NJ) produit de tels arbres sans racine.
3. Clustering chevauchant vs non chevauchant
Les algorithmes de clustering chevauchant autorisent la présence d’un même objet dans deux clusters différents qui ne sont pas inclus l’un dans l’autre. Cela signifie que les clusters d’un même niveau ne sont pas exclusifs. Des clusters chevauchants ne peuvent pas former une hiérarchie au sens strict, mais on parle tout de même de clustering hiérarchique chevauchant s’il y a au moins deux niveaux intermédiaires entre la racine et les feuilles (les niveaux étant définis par la relation d’inclusion).

La plupart des algorithmes courants ne sont pas chevauchants. Pourtant les classifications chevauchantes peuvent être très pratiques dans certains cas. On les recommande par exemple pour les clés d’identification lorsque certaines espèces présentent des caractères polymorphes. Imaginez que vous soyez en train de déterminer un spécimen d’une espèce d’oiseau dont certains individus ont un plumage rouge et d’autres un plumage noir. La clé vous demandera à un moment donné de suivre un chemin différent en fonction de la couleur de votre spécimen. Si la clé est bien conçue vous parviendrez à identifier l’espèce quelle que soit la couleur de votre spécimen. Il faut donc que l’espèce en question soit à la fois dans le cluster rouge et dans la cluster noir.
4. Clustering monothétique vs polythétique
Un algorithme de clustering monothétique se fonde sur une seule et unique propriété pour produire une partition, par exemple les fumeurs vs les non-fumeurs. Dans le cas d’une classification hiérarchique chaque partition d’un cluster est justifiée par un seul critère, mais ce critère peut être différent pour chacune. C’est le cas par exemple dans une clé d’identification où on suit un chemin en répondant à des questions successives. Chaque question n’est posée qu’une seule fois le long du chemin menant de la racine au nom de l’espèce. Chaque bifurcation correspond à une question sur un seul critère. Lorsqu’on construit une classification monothétique la difficulté consiste généralement à déterminer l’ordre optimal des critères à considérer.

La plupart des algorithmes courants font à l’inverse du clustering polythétique, c’est-à-dire qu’ils produisent des regroupements en considérant plusieurs critères à la fois. C’est nécessairement le cas de tous les algorithmes qui prennent en entrée une matrice de dissimilarité, puisque les indices de dissimilarités sont calculés en prenant en compte toutes les propriétés pertinentes des objets pour la tâche de classification à effectuer. Les groupes d’objets similaires peuvent alors être caractérisés par une liste de propriétés rencontrées fréquemment au sein de ce groupe sans qu’aucune ne soit nécessaire ni suffisante pour appartenir à ce groupe.
5. Clustering agglomératif vs divisif
Lorsqu’on construit des groupes imbriqués il y a deux grandes stratégies possibles. On peut partir des singletons (les objets isolés dans leurs propres groupes) et les fusionner dans des clusters de plus en plus inclusifs. C’est la stratégie ascendante ou clustering agglomératif.

L’UPGMA (ou average-linkage) appartient à cette catégorie d’algorithmes. Les algorithmes de clustering agglomératif se distinguent par la manière de choisir la paire de clusters à fusionner ainsi que par la formule qu'on utilise pour combiner les dissimilarités des clusters fusionnés. Voici quelques exemples de formules courantes de fusion :
| Algorithme | Formule de liaison |
| WPGMA (weighted-linkage) |  |
| UPGMA (average-linkage) |  |
| WPGMC (median-linkage) |  |
| UPGMC (centroid-linkage) |  |
| Single-linkage |  |
| Complete-linkage |  |
 est la fonction de dissimilarité.
est la fonction de dissimilarité.  ,
, 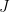 et
et  désignent des clusters, et
désignent des clusters, et 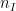 est le nombre d’éléments de .
est le nombre d’éléments de .Ces 6 algorithmes fusionnent toujours la paire de clusters la moins dissimilaire, mais d’autres critères existent. La méthode de Ward par exemple cherche à minimiser la dispersion au sein des clusters. Pour ce faire, on choisit la paire de clusters dont la fusion augmente le moins la variance intra-cluster.
La stratégie opposée consiste à partir de l’ensemble des objets et tenter de les scinder en des groupes de plus en plus restreints. C’est la stratégie descendante ou clustering divisif. Le problème principal avec cette seconde stratégie est que tester l’ensemble des partitions possibles d’un ensemble de n objets à chaque étape de scission a un cout prohibitif en termes de temps de calcul. Il y a ainsi 
L’algorithme divisif polythétique DIANA par exemple fonctionne avec un mécanisme qui ressemble un peu à la manière dont un parti politique peut se diviser à cause de conflits internes. D’abord l’élément le plus dissimilaire quitte le cluster et en crée un nouveau. Ensuite d’autres éléments le suivent un par un jusqu’à ce qu’on atteigne un équilibre. Pour les algorithmes divisifs monothétiques on peut réaliser une analyse d’association des différentes propriétés des objets afin de déterminer l’ordre dans lequel elles doivent être considérées. L’analyse d’association doit alors être répétée à chaque étape de scission puisque les propriétés déjà utilisées aux étapes précédentes doivent être éliminées de l’analyse.
6. Clustering direct vs itératif
Tous les algorithmes que nous avons mentionnés jusqu’ici font du clustering direct. Cela signifie qu'on construit la classification en une seule passe. Dans le cas d’un clustering hiérarchique, une fois qu’un niveau de la classification a été construit, il n’est pas remis en cause lors des étapes ultérieures. Pour l’UPGMA par exemple, lorsque deux clusters ont été fusionnés, leurs éléments ne peuvent plus être déplacés à d’autres endroits de la classification au cours des étapes suivantes. Les algorithmes hiéarchiques directs qui cherchent à respecter un critère d’optimalité le font donc localement, en fusionnant par exemple les deux clusters les moins dissimilaires.
Les algorithmes de clustering itératif cherchent au contraire à respecter un critère d’optimalité global, c’est-à-dire sur l’ensemble de la classification. L’algorithme tente alors divers réarrangements dans la classification, déplaçant des éléments à des endroits susceptibles d’améliorer la classification selon le critère d’optimalité auquel il se plie. On peut par exemple chercher à maximiser le coefficient de corrélation cophénétique, minimiser la longueur totale de l’arbre (la somme de toutes les branches), minimiser la somme des carrés des résidus, ou tout autre critère pertinent dans le cadre de l’étude en question. Un algorithme itératif prend donc souvent comme point de départ une classification produite par un algorithme direct.
Certains algorithmes directs peuvent être considérés comme des heuristiques pour des critères globaux, c’est-à-dire des algorithmes gloutons (greedy algorithm) cherchant à obtenir un résultat globalement optimal en réalisant étape par étape des choix localement optimaux. Il n’est pas toujours évident de savoir si un algorithme direct correspond à un critère global, et si c’est le cas, lequel. Étant par définition des heuristiques, les algorithmes gloutons n’ont en effet aucune garantie de trouver la solution globalement optimale. Ils permettent toutefois de trouver des solutions généralement pas trop éloignées.
L’UPGMA est ainsi un algorithme glouton qui correspond au critère global de minimisation de la longueur totale d’un arbre ultramétrique dont on a optimisé les longueurs de branches de manière à minimiser la norme 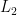
Conclusion
Le choix d’un algorithme de clustering est une décision cruciale dans toute analyse de données. Elle dépend d’une multitude de facteurs : la nature des données, la structure des groupes recherchés, la manière dont les dissimilarités sont mesurées, etc. Chaque algorithme possède ses forces et ses faiblesses, que ce soit en termes de complexité computationnelle (temps de calcul et mémoire nécessaires), de flexibilité, de biais, de capacité à révéler des motifs pertinents, etc.
Cette diversité d’approches, bien que précieuse, rend parfois difficile la tâche de sélectionner l’outil le mieux adapté. L’un des dangers évidents, est de choisir l’algorithme qui donne la classification que nous préférons (correspondant à des attentes subjectives), puis d’essayer de justifier ce choix à postériori. Ce genre de mauvaise pratique est l’équivalent du p-hacking en statistiques. En tant que bioinformaticien ou data scientist, il est donc essentiel de bien comprendre les implications théoriques et pratiques de chaque algorithme, puis d’évaluer les résultats grâce à des techniques de validation. Sans une réflexion approfondie sur les objectifs de l’analyse, il est facile de s’égarer dans le vaste paysage des méthodes de clustering.
Références
- Giordani P., Ferraro M. B., F. (2020). An Introduction to Clustering with R. Springer Verlag, Singapore.
- Moulton V., Spillner A., & Wu T. (2018). UPGMA and the normalized equidistant minimum evolution problem. Theoretical Computer Science, 721:1-15.
- Murtagh F., & Legendre P. (2014). Ward’s hierarchical agglomerative clustering method: which algorithms implement Ward’s criterion? Journal of classification, 31:274-295.
- Everitt B. S., Landau S., Leese M., & Stahl D. (2011). Cluster Analysis. Wiley; 5th Edition.
- Gascuel, O. & Steel M. (2006). Neighbor-joining revealed. Molecular biology and evolution, 23(11):1997-2000.
- Sneath P.H.A. & Sokal R.R. (1973). Numerical Taxonomy: The Principles and Practice of Numerical Classification. W. H. Freeman, San Francisco.
Je vous encourage aussi à consulter ma vidéo sur l'UPGMA pour un aperçu rapide des algorithmes de clustering hiérarchique non chevauchant polythétique agglomératif direct : https://www.youtube.com/watch?v=t93uaoQh25s
Merci à MarionP et ZaZo0o pour la relecture.
Laisser un commentaire