

Catégorie : Découverte
-
L'analyse de données RNA-seq : mode d'emploi

Un jour, un biologiste se pointe chez vous avec d'une part un disque dur externe dans la main, d'autre part l'air soucieux. Il veut que vous analysiez ses données RNA-seq. Le disque, c'est parce qu'il a environ 50Gb de données à vous transmettre ; l'air soucieux, c'est parce qu'elles ont coûté dans les 15'000 euros, et…
-
L'indice de Jaccard, pas qu'une histoire de mailles…

J'ai utilisé dernièrement l'indice de Jaccard pour comparer des ensembles de mots. Comme c'est une mesure assez classique et plutôt utile, j'ai décidé de vous en parler un peu. Donc voici une introduction à l'indice de Jaccard, à ne pas confondre avec le pull Jacquard, ce n'est pas du tout la même chose. L'indice de…
-
Jouez avec vos données : utilisez un ORM
Il y a quelques temps, je vous ai parlé de base de données, un super moyen pour structurer vos données. Vous êtes maintenant j'en suis sûr, des professionnels du SELECT, des JOIN et autres ALTER. C'est bien, très bien même, mais maintenant je vais vous apprendre à vous en passer. Et oui, la ligne de…
-
DNase-seq, FAIRE-seq, ChIP-seq, trois outils d'analyse de la régulation de l'expression des gènes

La régulation de la transcription est un processus indispensable aux cellules pour permettre leur différenciation, exprimer leur spécificité, assurer leur développement, leur prolifération ou encore pour leur permettre de s'adapter à un environnement. L'étude de la régulation de la transcription passe par l'identification d'éléments clés gouvernant ces processus biologiques.Ces éléments de régulations se distinguent en…
-
Clusters et pipelines avec LSF

Aujourd'hui petit mash-up de deux articles précédemment publiés dans nos colonnes. Comme je l'avais promis, je vais vous présenter ma méthode pour faire du pipelining avec le gestionnaire de ressources de notre cluster. Si vous n'avez pas compris la phrase précédente, je vous invite à aller (re-)lire l'article sur les pipelines et celui sur les…
-
Un tour d'horizon des bases de données consacrées au métabolisme
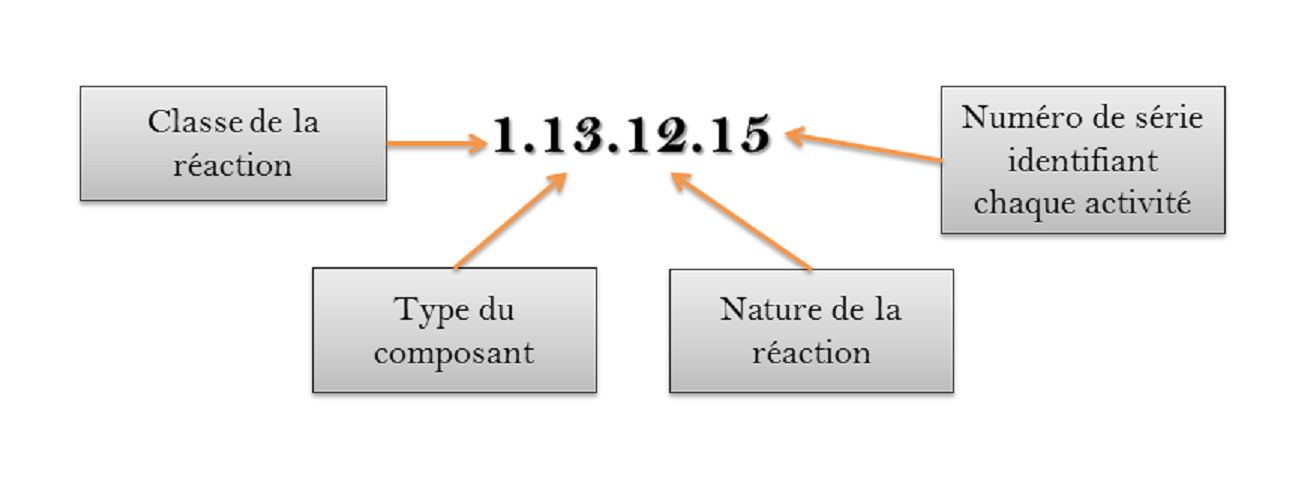
La toute première activité enzymatique a été découverte par Anselme Payen, un chimiste industriel français qui a piqué, grâce à son génie, la domination du marché de borax aux néerlandais. C'était une α-amylase, isolée à partir d'un extrait de malt, et capable de découper l'amidon en glucose. Nommée initialement diastase (synonyme d'"enzyme" à l'heure actuelle),…
-
Les identifiants : a (name)space oddity

Sur Bioinfo-fr.net, nous avons plusieurs fois parlé des bases de données biologiques. Que ce soit du point de vue de la gestion, de l'exploitation ou même du stockage physique. J'aimerai revenir aujourd'hui sur un souci qui se présente souvent lors de l'exploitation de plusieurs bases de données : les identifiants. Un objet biologique dans une base…
-
Que faire de nos données biologiques produites ?

Qu'on soit affilié à un laboratoire de génomique, d'imagerie ou encore de protéomique nous avons tous un point commun : nous devons avoir un moyen fiable et dont la pérennité ne laisse pas à désirer pour ce qui est de la gestion de nos données produites/recueillies. Les vieux sages vous diront, à juste titre, qu'il n'existe…