

Catégorie : Découverte
-
Bioservices, un module Python très utile

Dans notre domaine si vaste, il existe de nombreuses bases de données (cf. Bases de données, notions par nahoy), et parmi ces bases, un certain nombre d'entre elles propose un service web pour accéder à leurs données à partir d'un script. Le problème principal qui peut nous freiner, ou nous faire peur, lorsque l'on se…
-
Introduction aux ontologies
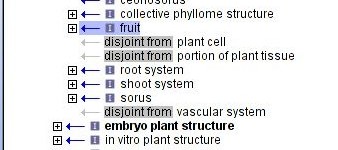
Qu'est-ce que c'est ? Les ontologies telles qu'on les emploie en informatique (car le concept est philosophique avant tout) ont d'abord été mises au point pour l'intelligence artificielle. Leur objectif est de décrire ce qui existe et la définition formelle est assez complexe mais je vais m'efforcer de présenter les choses plus simplement. Dans sa définition,…
-
Single-cell sequencing : le séquençage à la cellule près

Dans la grande famille du séquençage, on distingue le DNAseq et le RNAseq. Le premier capture la séquence d'ADN contenue dans un organisme, un tissu, une tumeur. C'est un peu comme décompiler le code source d'un être vivant pour comprendre comment il fonctionne. Le postulat de l'ADN est qu'il est sensé être le même dans…
-
Assembler un génome sur un Raspberry Pi

Assembler un génome est une tâche fastidieuse et surtout très coûteuse. Pour un génome de 100 Mbp (Million de paires de bases), Velvet ou SOAPdenovo utilisent 20 à 30 Go de mémoire, voire plus. Je voudrais partager avec vous une idée complètement farfelue qui nous est venue et qui nous a fait gagner (Guillaume Rizk et…
-
ELIXIR, un savant mélange de pays

Vous avez peut-être entendu parler d'ELIXIR récemment, car la France vient de rejoindre le projet. Mais ELIXIR, c'est quoi ? Pour faire simple, ELIXIR c'est la réponse aux défis suivants, chers aux chercheurs en Science de la Vie : Ces défis étant justement d'une portée trop vaste pour être géré par une seule institution ou un seul…
-
Julia : le successeur de R ?
Actuellement le langage R est incontournable pour qui veut manipuler des données en bioinformatique, en particulier pour l'analyse statistique. Mais un successeur est en passe de s'imposer : Julia, combinant puissance du langage avec les fonctionnalités de R, et comblant les nombreux défauts de ce dernier - mais plus encore ! Voici une présentation de ce tout…
-
RSG Suisse

Création du groupe régional Suisse des étudiants (SC-RSG Switzerland) appartenant à la société internationale de biologie computationnelle (ISCB) Bonjour à tous, Par la présente, je vous annonce la création du groupe régional Suisse du conseil des étudiants appartenant à la société internationale de biologie computationnelle. La Bioinformatique est largement implantée en Suisse grâce à l’institut…
-
European Molecular Biology Laboratory (EMBL)

Voici un article d'un nouveau genre sur bioinfo-fr : après les lieux pour vous former à la bioinformatique, voici les lieux où postuler pour un stage ou pour travailler une fois votre diplôme en poche. Et aujourd'hui je m'attaque à une grosse pièce puisque je vais vous parler de l'EMBL (European Molecular Biology Laboratory ). Un…