

Catégorie : Découverte
-
Les mystérieuses cités d'or

La bioinformatique est un domaine de recherche donc, avec régulièrement de nouveaux logiciels et très souvent* votre premier contact avec ce nouveau logiciel se fait via la forge logiciel GitHub. Sur GitHub la première chose que l'utilisateur voit c'est le Readme (pour plus de détails sur ce fichier aller lire cet excellent billet de blog).…
-
Métabarcodes de l'ADN environnemental

L'une des technologies en génomique les plus prometteuses pour l'évaluation de la biodiversité est le métabarcode (de l'anglais metabarcoding) de l'ADN environnemental (ADNe). J'ai travaillé longuement sur ces méthodes et développé plusieurs workflows pour traiter et analyser les données de métabarcodes. J'ai notamment été en charge du traitement des données génomiques récoltées par l’expédition scientifique…
-
Pourquoi certains fichiers FASTQ finissent par 001 ?

Sur le chan IRC du blog, un de nos membres se demandait pourquoi les noms de fichiers FASTQ devait finir par _001.fastq sur la plateforme de cloud computing d'Illumina BaseSpace. Mais avant de répondre à cette question pressante, repartons du début. Les fichiers FASTQ En cette période de domination du séquençage haut débit de l'ADN,…
-
La transcriptomique spatiale
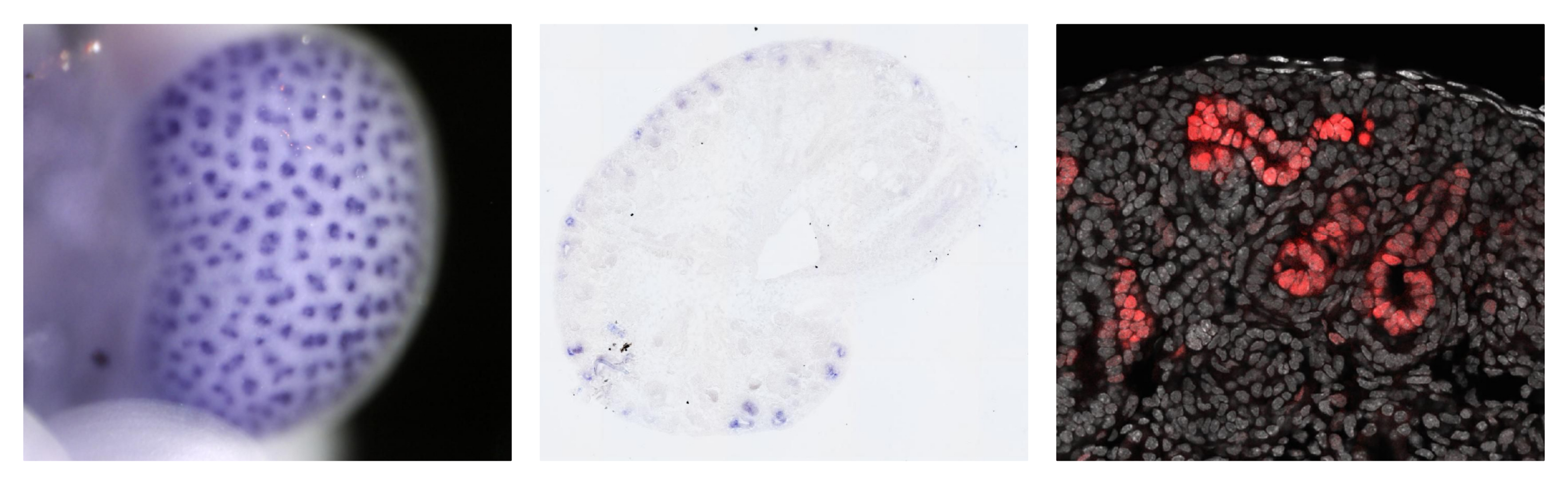
Non, on ne va pas partir faire du RNA-seq dans la station spatiale internationale, rassurez-vous. Je vais vous parler de cette (relativement) nouvelle technique qui permet en une seule expérience de mesurer l'expression des gènes et de localiser cette expression dans un organe plus ou moins complexe. Pour faire une analyse à large échelle du…
-
1… 2… 3… 4C ! Ou comment capturer l'état de la chromatine.
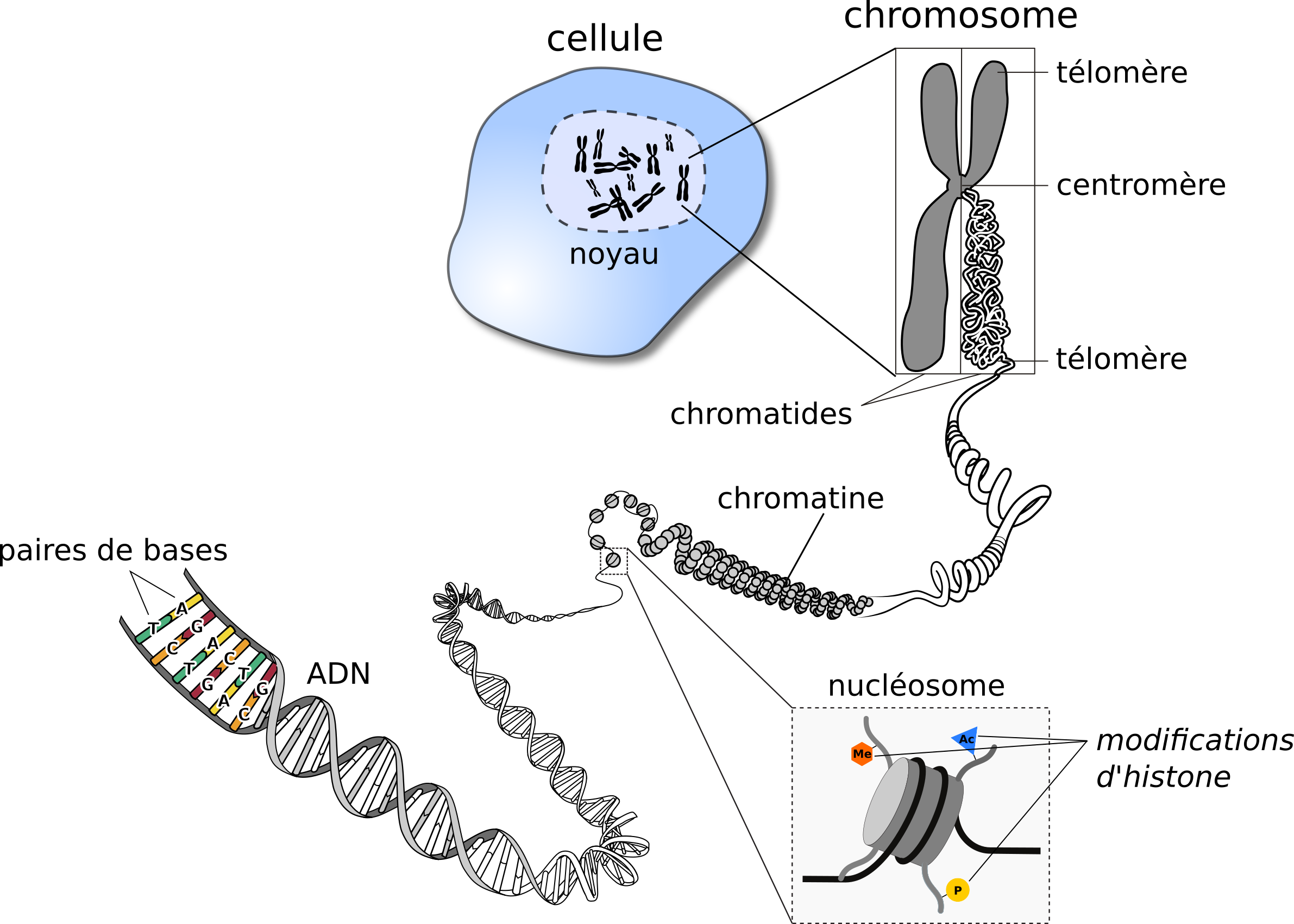
Une cellule eucaryote comporte un noyau qui contient l’information génétique portée par les chromosomes, eux même composés d’ADN. Chez l'Homme, l'ADN des chromosomes mis bouts à bouts mesure 1,9 mètre de long. Or, tout ce matériel génétique doit tenir dans le noyau des cellules, qui lui mesure 5 à 7 micromètres de diamètre (en moyenne…
-
Contrarié par les diagrammes de Venn ? Découvrez les diagrammes UpSet
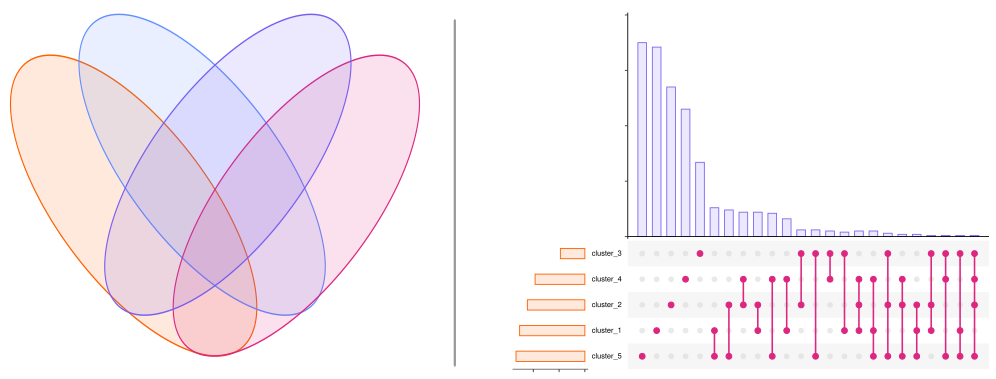
Titre incluant un moyen mnémotechnique ;D Avec ses cercles entrecroisés, on ne présente plus le célèbre diagramme de Venn. Cette représentation est utilisée dans le cas où l'on souhaite représenter le recoupement de données de nombre fini selon plusieurs variables qualitatives. De façon plus simple lorsqu'on a 2 variables qualitatives : combien d'éléments présents dans la…
-
Génomique des paysages

Introduction « Génomique des paysages » cela sonne comme le titre d’une œuvre d’Eduardo Kac. Ce nom un peu post-moderne désigne en fait une discipline scientifique qui a connu une expansion fulgurante au cours de la dernière décennie. Les enjeux environnementaux et de conversation actuels ont rendus pressante la nécessité de mieux comprendre et décrire les espèces…
-
Sept problèmes fascinants posés par les récepteurs olfactifs
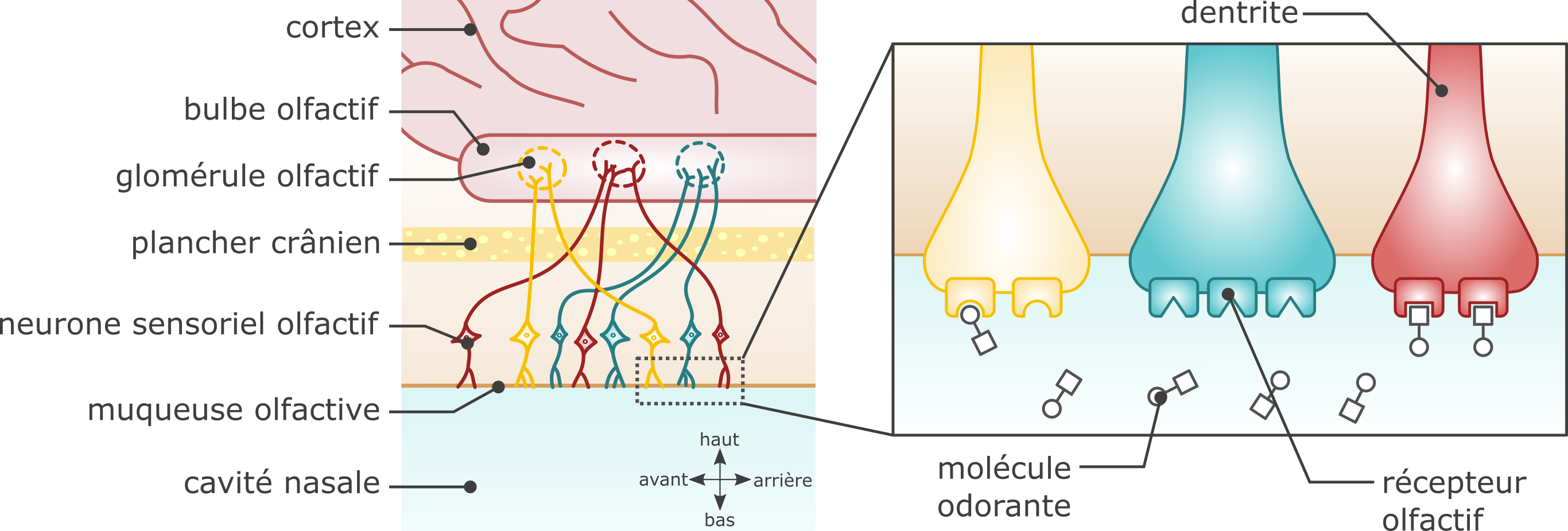
Le cinquième va vous étonner ! Introduction : l'olfaction, un sens assez bien compris et compréhensible L’olfaction n'est peut-être pas le plus noble des sens, comparé à la vue ou l’ouïe par exemple, mais il s'agit d'un sens assez bien compris aujourd'hui. C'est notamment grâce aux travaux des biologistes Linda B. Buck et Richard Axel, récompensés par…