


Le traitement et l’analyse de données sont une part importante des tâches demandées à un bioinformaticien. L’utilisation de R facilite grandement la manipulation des données et permet également leur représentation de multiples façons. Malgré le potentiel de R, ce dernier est souvent sous-exploité à cause d’une syntaxe parfois trop complexe. Je vais vous présenter aujourd’hui un package R, « ggplot2 », permettant la production de graphiques très élaborés en peu de temps.
Un peu d’histoire
Ggplot2 est un "package" R créé par Hadley Wickham en 2005. Pour ceux qui ne le connaîtraient pas, Hadley Wickham est un peu le dieu de R depuis quelques années. Il est à la base de "packages" facilitant la vie des utilisateurs de R tels que ‘plyr’, ‘reshape2’, ‘lubridate’, ‘stringr’, ‘tesJhat’. Vous pouvez en apprendre plus sur Hadley Wickham ici. Ggplot2 s’inspire en partie des travaux de Leland Wilkinson décrits dans « Grammar of Graphics - a general scheme for data visualization which breaks up graphs into semantic components such as scales and layers ». Sans rentrer dans les détails de cet ouvrage, on peut résumer le principe de base qui est de séparer les données de la représentation graphique et de diviser la représentation en éléments de base tels que les courbes, les axes ou les labels. Ça peut sembler un peu confus au début mais cette façon de faire présente de nombreux avantages. Une fois les données mises en forme, il ne sera plus nécessaire d’y revenir. Il est alors possible de les représenter sous forme de plot, de courbes, de barplot, et de bien d’autres façons en utilisant juste le bon outil. Rentrons maintenant un peu dans le détail.
Installation
L’installation des "packages" R est en général très simple. Ggplot2 ne fait pas exception à la règle. Dans votre console R, tapez simplement
|
1 |
install.packages('ggplot2') |
et le package devrait s’installer tout seul. En cas de problème je vous renvoie à la doc de ggplot2.
Principes de base de ggplot2
Dans ggplot2, un "plot" se décompose de la manière suivante Plot <- data + Aesthetics + Geometry Si le premier terme n’est pas vraiment mystérieux, les deux autres sont déjà un peu moins communs. Pour les données, celles-ci doivent prendre une structure particulière mais nous y reviendrons un peu plus tard. Sous le terme "Aesthetics" on va retrouver tout ce qui concerne les couleurs, les tailles, les formes, les labels mais aussi quelles données doivent être considérées en x et en y par exemple. "Geometry" va regrouper les options concernant les types de graphique (plot, histogramme, heatmap, boxplot, etc…). Ces différents éléments vont être combinés dans un objet à partir duquel on va pouvoir faire les représentations dans une fenêtre graphique ou dans un fichier. Et lorsque l’on voudra changer la couleur ou la forme ou le type de graphique il suffira de modifier ce paramètre dans l’objet sans avoir besoin de toucher aux autres puis de faire à nouveau la représentation graphique. Ça peut paraître un peu confus au début mais quelques exemples vont vite éclaircir le tout.
Avant toutes choses les données
Les données sont bien sûr la base. La structure des données peut être un peu déroutante au début mais on s’y fait assez vite. Il faut mettre les données dans une table de telle sorte qu’une des colonnes de la table contiendra les données sur x, une autre les données sur y et encore une autre les différentes conditions. Prenons l’exemple d’une cinétique. On imagine qu’on a 13 points, un toutes les 5 minutes pendant 1 heure et qu’on compare 2 conditions pour une réaction enzymatique. Le résultat qu’on observe sera une densité optique (D.O.) à 280nm. On aura la structure suivante :
| Time | Abs | Cond |
| 0 | 0.1 | Without enzyme |
| 5 | 0.09 | Without enzyme |
| 10 | 0.12 | Without enzyme |
| 15 | 0.13 | Without enzyme |
| 20 | 0.11 | Without enzyme |
| 25 | 0.07 | Without enzyme |
| 30 | 0.09 | Without enzyme |
| 35 | 0.1 | Without enzyme |
| 40 | 0.11 | Without enzyme |
| 45 | 0.11 | Without enzyme |
| 50 | 0.13 | Without enzyme |
| 55 | 0.1 | Without enzyme |
| 60 | 0.07 | Without enzyme |
| 0 | 0.08 | With enzyme |
| 5 | 0.12 | With enzyme |
| 10 | 0.18 | With enzyme |
| 15 | 0.29 | With enzyme |
| 20 | 0.46 | With enzyme |
| 25 | 0.89 | With enzyme |
| 30 | 1.12 | With enzyme |
| 35 | 1.34 | With enzyme |
| 40 | 1.45 | With enzyme |
| 45 | 1.54 | With enzyme |
| 50 | 1.59 | With enzyme |
| 55 | 1.62 | With enzyme |
| 60 | 1.61 | With enzyme |
Cette structure ressemble à ce qu'on peut trouver dans une table d'une base de données. Il y a un peu de redondance d'information mais c'est très lisible. J’ai mis ce tableau dans un petit fichier que l'on va charger dans R.
|
1 |
data_kinetic_01 < ;- read.delim("data_kinetic_01.txt") |
Premier "plot"
Commençons par faire un plot simple, la DO en fonction du temps avec des couleurs et des formes différentes pour les 2 échantillons.
|
1 |
p < ;- ggplot(data=data_kinetic_01, aes(x=Time, y=Abs, colour=Cond, shape=Cond)) |
Décryptons un peu cette instruction. On créé un objet ggplot et on lui indique quelles données il faut utiliser (data=data_kinetic_01). Puis les paramètres de "Aesthetics" sont définis (aes(x=Time, y=Abs, colour=Cond, shape=Cond)). Dans cette commande, il est indiqué d’utiliser la colonne Time pour x et la colonne Abs pour y. Pour les couleurs et les formes la colonne Cond sera utilisée. Ce paramètre peut être plus difficile à comprendre car dans la colonne Cond, il n'y a aucune indication de couleur ou de forme. En réalité ggplot2 définit lui même les couleurs et formes à utiliser. La colonne Cond va servir à indiquer le groupe auquel chaque point appartient. On voit que dans notre cas, cette colonne contient 2 valeurs distinctes "without enzyme" et "with enzyme". Ggplot2 va donc définir 2 couleurs et 2 formes de points. La partie "geometry" est ensuite ajoutée par la commande ci-dessous. Le but étant de dessiner des points, on va donc logiquement utiliser la commande geom_poinet simplement l'ajouter à l’objet qui vient d'être créé.
|
1 |
p < ;- p + geom_point(size=4) |
Et voilà notre objet est prêt. Il ne reste plus qu’à le représenter dans une fenêtre graphique classique.
|
1 |
print(p) |
Ce qui donne le "plot" suivant :
Le plot correspond à ce qu’on attend. On voit bien les 2 séries de données avec des formes et couleurs différentes. A partir de là, on peut agrémenter un peu le graph en ajoutant un titre par exemple ou en reliant les points.
|
1 2 |
p < ;- p + ggtitle("My beautiful enzyme")<br> p < ;- p + geom_line(size=2) |

Il est aussi possible d’ajouter une courbe lissée.
|
1 |
p < ;- ggplot(data=data_kinetic_01, aes(x=Time, y=Abs, colour=Cond, shape=Cond)) + geom_point(size=4) p < ;- p+ geom_smooth() |

L'ajout d'éléments à la figure est très simple et de nombreuses fonctions sont disponibles. Il faudra juste parcourir la documentation pour trouver celle qui convient mais les noms sont assez explicites et leur utilisation plutôt intuitive. A partir des mêmes données on peut par exemple représenter les données sous forme d’histogramme.
|
1 |
p < ;- ggplot(data=data_kinetic_01, aes(x=Time, y=Abs, fill=Cond)) + geom_histogram(stat='identity') |

La valeur identity du paramètre stat indique à la fonction d’utiliser toutes les valeurs du tableau au lieu de faire un histogramme de répartition. Les barres sont empilées alors qu’on les voudrait séparées. Le paramètre position avec la valeur dodge va séparer les barres.
|
1 |
p < ;- ggplot(data=data_kinetic_01, aes(x=Time, y=Abs, fill=Cond)) + geom_histogram(stat='identity', position='dodge') |

Et voilà. Une fois la figure finie, il est possible de l'exporter dans une image ou dans un fichier pdf est à l'aide de la fonction ggsave
|
1 |
ggsave(plot=p, file="kinetics_plot_01.png") |
l'extension du fichier servira à indiquer à ggsave le format de fichier voulu.
Allons plus loin
Bon, certes c’est assez sympa mais malgré tout ça reste assez basique et les fonctions de base de R font tout aussi bien presque aussi facilement. On va donc faire des choses un peu plus compliquées.
Histogrammes
Cette fois, les données seront générées de façon aléatoires : 3 conditions (A, B ou C) et 100 mesures pour chaque.
|
1 2 |
nb.samples=100<br> df2 < ;- data.frame(id = rep(1 :nb.samples, times=3), condition = factor( rep(c("A","B","C"), each=nb.samples)), value =  ;c(rnorm(nb.samples),rnorm(nb.samples, mean=.5, sd=2), rnorm(nb.samples, mean=2.1, sd=0.5))) |
Pour observer la répartition des valeurs, il suffit d'utiliser la fonction geom_histogramm
|
1 2 |
p < ;- ggplot(df, aes(x=value))<br> p < ;- p + geom_histogram(binwidth=.5, colour="black", fill="white") |

Il est possible d'ajouter une ligne correspondant à la moyenne.
|
1 |
p < ;- p + geom_vline(aes(xintercept=mean(value, na.rm=T)), color="red", linetype="dashed", size=1) |

On passe à un fond blanc pour faciliter une éventuelle impression.
|
1 |
p < ;- p + theme_bw() |

Imaginons maintenant que l'on souhaite observer la répartitions des valeurs pour chaque condition séparée.
|
1 2 3 |
p < ;- ggplot(df, aes(x=value, fill=condition))<br> p < ;- p + geom_histogram(binwidth=.5, colour="black")<br> p < ;- p + theme_bw() |

Cette représentation n’est pas idéale. Pours séparer les valeurs dans des plots différents, il va falloir utiliser une nouvelle fonction facet_grid. Les plots peuvent être disposés horizontalement.
|
1 |
p < ;- p + facet_grid( . ~ condition) |

ou verticalement.
|
1 |
p < ;- p + facet_grid( condition ~ .) |

Un peu de décoration.
|
1 2 |
p < ;- p + ggtitle("yet another ggplot2 histogram")<br> p < ;- p + xlab(label="my favorite measurement") |

Pour completer la figure avec quelques informations sur les distributions il suffit d'utiliser le package plyr, créé par le même développeur. Je ne rentre pas dans le détail de plyr, je le décrirai dans un autre article.
|
1 |
library(plyr) |
A l’aide de plyr on calcule les moyennes par condition.
|
1 |
df.stats < ;- ddply(df, "condition", summarise, value.mean=mean(value), value.sd=sd(value)) |
On ajoute des lignes verticales au niveau des moyennes calculées.
|
1 |
p < ;- p + geom_vline(data=df.stats, aes(xintercept=value.mean),  ;linetype="longdash", size=1, colour="black") |

Puis on trace les lignes correspondant aux limites à plus ou moins 3 écart-types de la moyenne.
|
1 2 |
p < ;- p + geom_vline(data=df.stats, aes(xintercept=value.mean - 3*value.sd), linetype="dotted", size=1, colour="black")<br> p < ;- p + geom_vline(data=df.stats, aes(xintercept=value.mean + 3*value.sd), linetype="dotted", size=1, colour="black") |

Boxplots
A partir des même données on peut aussi dessiner des "boxplots".
|
1 |
p < ;- ggplot(data=df, aes(x=condition, y=value)) p < ;- p + geom_boxplot() |
La fonction fait ce qu'on a attend d'elle, des "boxplots" basiques

Ajoutons les points
|
1 |
p < ;- p + geom_point() |

Comme le graphe manque un peu de lisibilité, on colore les "boxplots" en fonction des conditions et on disperse les points sur toute la largeur.
|
1 2 3 |
p < ;- ggplot(data=df, aes(x=condition, y=value, fill=condition))<br> p < ;- p + geom_boxplot()<br> p < ;- p + geom_jitter(position = position_jitter(width = .2)) |
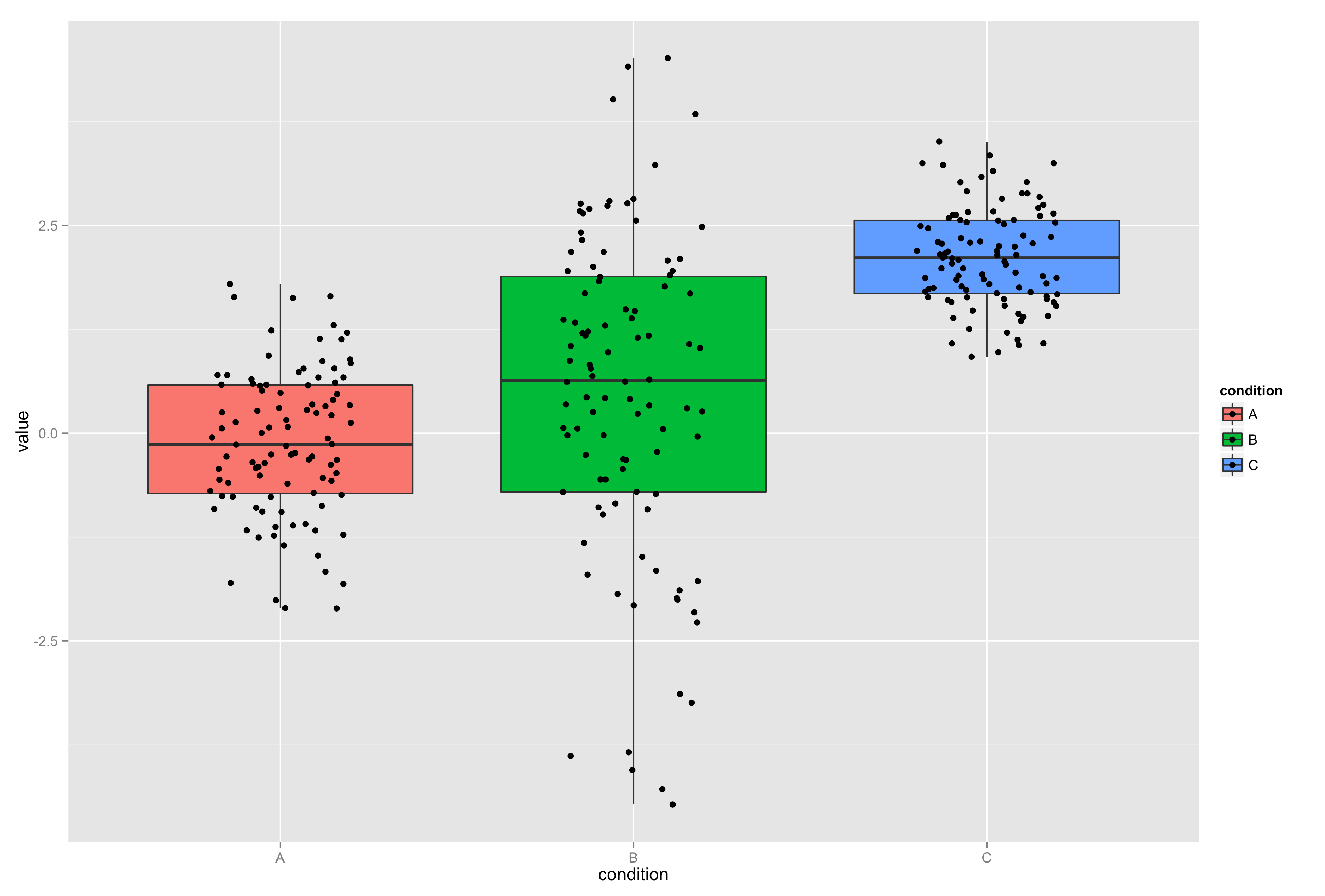
On peut, si on le souhaite, relier les points entre eux. Ils seront reliés par leur rang dans le tableau
|
1 2 3 4 |
p < ;- ggplot(data=df, aes(x=condition, y=value, fill=condition))<br> p < ;- p + geom_boxplot()<br> p < ;- p + geom_point(aes(shape=condition), size=3)<br> p < ;- p + geom_line(aes(group=id), linetype='dashed') |

Pour personnaliser un peu plus le graph avec un fond blanc et en éliminant la légende des abscisses, il faudra utiliser la fonction theme
|
1 2 |
my.theme < ;- theme_bw()+ theme(axis.text=element_text(size=16), axis.title.x=element_blank())<br> p < ;- p + my.theme |

Scatterplots
Un dernier exemple avec cette fois des "scatterplots". On utilisera la fonction mvrnorm du package MASS pour générer les données
|
1 2 3 4 5 6 7 8 |
library(MASS)<br> set.seed(123)<br> nb.samples < ;- 25<br> correlation.group.1 < ;- 0.65<br> m.data.group.1 < ;- mvrnorm(nb.samples, mu = c(10,5), Sigma = matrix(c(1,correlation.group.1,correlation.group.1,1), ncol = 2), empirical = TRUE)<br> correlation.group.2 < ;- 0.85<br> m.data.group.2 < ;- mvrnorm(nb.samples, mu = c(15,6), Sigma = matrix(c(1,correlation.group.2,correlation.group.2,1), ncol = 2), empirical = TRUE)<br> df < ;- data.frame(id = rep(1 :nb.samples, times=2), condition = factor( rep(c("A","B"), each=nb.samples)), protein.1 = c(m.data.group.1[,1],m.data.group.2[,1]), protein.2 = c(m.data.group.1[,2],m.data.group.2[,2])) |
Représentons dans un premier temps les points.
|
1 2 |
p < ;- ggplot(data=df, aes(x=protein.1, y=protein.2))<br> p < ;- p + geom_point(size=4) |

Puis ajoutons une courbe de régression.
|
1 |
p < ;- p + stat_smooth() |

La fonction stat_smooth permet d'obtenir la courbe passant au plus près de l'ensemble des points. Cependant, on ne tient pas compte des différentes conditions. Pour les séparer, il faut utiliser l'argument colour.
|
1 2 |
p < ;- ggplot(data=df, aes(x=protein.1, y=protein.2, colour=condition, shape=condition))<br> p < ;- p + geom_point(size=4) |

On choisi d'ajouter une droite de régression et non plus une courbe lissée en utilisant la méthode lm en paramètre à la fonction stat_smooth
|
1 |
p < ;- p + stat_smooth(method = "lm") |

On rajoute un peu de décoration, c'est toujours mieux
|
1 |
p < ;- p + theme_bw() p < ;- p + ggtitle("yet another ggplot2 scatterplot") |

Et on obtient nos points avec leur courbe de tendance respectives. Elles sont sur le même graphe mais il est très facile de les séparer.
|
1 |
p < ;- p + facet_grid(. ~ condition) |

Les 2 "plots" ont les mêmes échelles. Ce comportement est souvent intéressant mais dans notre cas, cela nuit un peu à la lisibilité. On élimine la contrainte d’échelle sur x.
|
1 |
p < ;- p + facet_grid(. ~ condition,scales="free_x") |

Et voilà on a 2 jolis graphes indépendants.
Pour aller plus loin
J’ai présenté quelques fonctions basiques de ggplot2. Le package permet beaucoup plus de choses et je n’ai pas encore tout exploré. Il existe pas mal de ressources pour aller plus loin.
- An extensive ggplot2 tutorial
- ggplot2 : Cheatsheet for Scatterplots
- ggplot2 : Cheatsheet for Visualizing Distributions
- ggplot2 : Cheatsheet for Barplots
- R-Bloggers entries on ggplot2
- Book : ggplot2 : Elegant Graphics for Data Analysis
- GRaphical Grammar with ggplot2
- A Layered Grammar of Graphics
- ggplot2 guide
- R Cookbook on ggplot2
- Documentation officielle de ggplot2
Le mieux étant de le découvrir petit à petit avec de vraies données. Merci aux relecteurs Maxi_zu, Estel et Bu pour leur corrections et leurs conseils avisés et surtout à Vincent Rouilly qui m’a fait découvrir ggplot2 et qui surtout a imaginé une bonne partie des exemples présentés ici.
{kind=link}
Laisser un commentaire