

Étiquette : Python
-
#JOBIM2018 : une étude de réseau
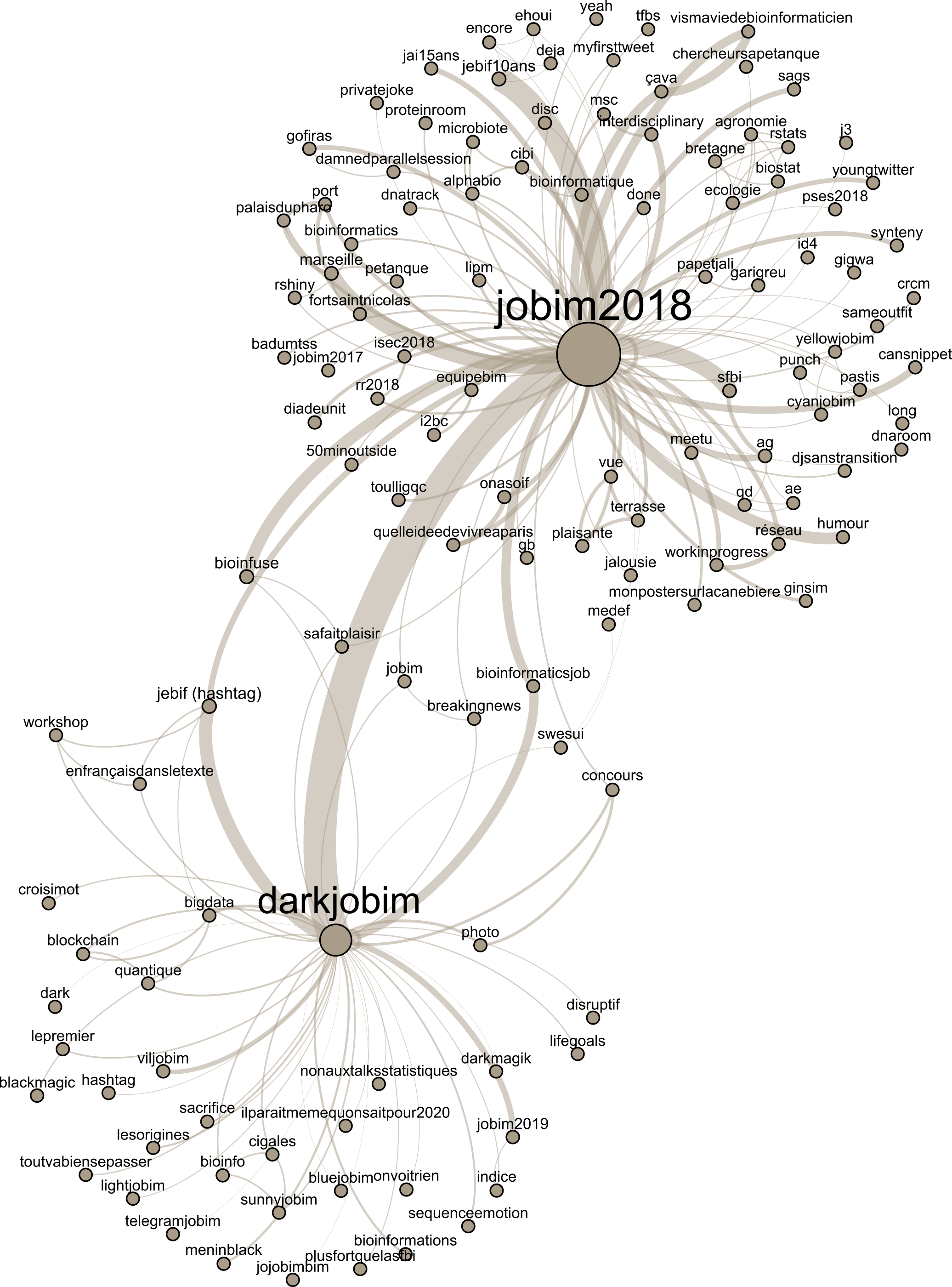
Comme une partie de la communauté bioinformatique française, et probablement du lectorat de ce blog, je me suis rendu à la 19è édition des Journées Ouvertes en Biologie, Informatique et Mathématiques (JOBIM). Celle-ci se tenait à Marseille, au Palais du Pharo, et pour celles et ceux d'entre vous curieux·ses de connaître le contenu scientifique, voilà…
-
Apprivoiser l'ami ursidé de Python : Pandas

Durant mon stage de M2, j’ai eu l’occasion de chatouiller ce drôle d’animal qu’est pandas. En effet, j’ai travaillé sur des données de protéomique contenues dans des fichiers tabulés. Il s'agissait de comparer la présence des protéines ou leur expression dans différents échantillons. Les abondances relatives (la variable étudiée) étaient indiquées pour les différentes protéines…
-
Customiser matplotlib (faire son matplotlibrc)

Suite à une mésaventure liée à matplotlib sur le chan IRC #bioinfo-fr (mésaventure suite aux fameuses erreurs de display ; si vous voulez tout savoir : si on configure mal son matplotlib on peut générer des erreurs qui font qu'on obtient des images vides… voir la partie sur le backend plus tard :o), j'ai parlé de la…
-
Jouer avec l'API de KEGG

Il n'est pas rare que nous ayons un jour besoin de récupérer des informations de la base de données KEGG (Kyoto Encyclopedia of Genes and Genomes). Cette base de données fournit un nombre conséquent d'informations sur les génomes et les réseaux de gènes mais également sur les voies métaboliques ou les maladies. Dans ces cas…
-
Ajoutez une interface graphique à votre script en 4 lignes avec Gooey
Vous venez de terminer votre analyse bio-informatique. Pour cette dernière, vous avez réalisé un script qui pour l'instant, il faut le dire, n'est pas du tout réutilisable par une tierce personne. Même vous dans 6 mois vous n'êtes pas sûr de vous souvenir de ce que vous avez fait. Pourtant, l'un des intérêts de la…
-
État de l'emploi bioinformatique en France : analyse des offres de la SFBI (2ème partie)

Nous revoilà pour la suite de notre premier article sur l'analyse des offres de la SFBI. On vous avait promis une analyse de l'évolution du marché, et c'est ce dont nous allons parler dans cet article. Je vous renvoie au premier article si vous voulez plus d'informations sur l'origine des données et la disponibilité du…
-
Snakemake aller plus loin avec la parallélisation

Bonjour à tous, bienvenue dans un nouvel épisode de tutoriels sur Snakemake (épisode précédent). Aujourd'hui nous allons voir ensemble comment paralléliser facilement par la donnée grâce à Snakemake. L'idée générale consiste à découper les fichiers bruts au début de notre pipeline et de les rassembler après les étapes lourdes en calcul. Nous allons également voir comment…
-
Écrire son parseur à la main — chroniques d'une mauvaise bonne idée

Partie 1 Où l'on prend conscience de l'existence de standards, et de leur nécessité. Tout petit programme s'éveillant au monde se trouvera un jour face à ses obligations : s’interfacer avec ce dernier. La lumière extérieure devra alors pénétrer son petit antre, apportant malicieusement l'information de mille autres petits programmes, si hétéroclites et désordonnés que nul…