


Écrire un algorithme de rev_comp ou complément inverse, on l'a tous déjà fait. Aujourd'hui c'est devenu un classique des cours d'algorithmique en étude de bioinformatique, c'est un algorithme simple mais qui demande de savoir utiliser les structures de contrôle de base. À la fois un bon exercice pratique et pédagogique, doit-il cependant rester implémenté comme à nos débuts ? Cette question m'a traversé l'esprit durant un cours où mon implémentation et celles de mes camarades étaient toutes différentes avec à chaque fois différents algorithmes de base. Ne voulant en rester là, j'ai donc passé mon week-end (et au final les deux mois suivants), à étudier quels étaient les algorithmes les plus performants parmi lesquels ceux que je vais vous présenter plus en avant.
Le complément inverse, c'est quoi exactement ?
Nous savons que l'ADN est composé de deux brins antiparallèles (si tu ne le savais pas je suis désolé je viens de te dévoiler un élément essentiel de tes cours de biologie). Pour les 3 statisticiens, l'informaticien et le physicien du fond on va résumer : l'ADN est un polymère composé de 2 chaînes parallèles mais dont l'orientation est opposée. Les deux orientations sont nommées 5'-3' ou 3'-5' (pour en savoir plus c'est par ici). Les deux polymères sont complémentaires : il y aura toujours un A en face d'un T, un C en face d'un G, et inversement.
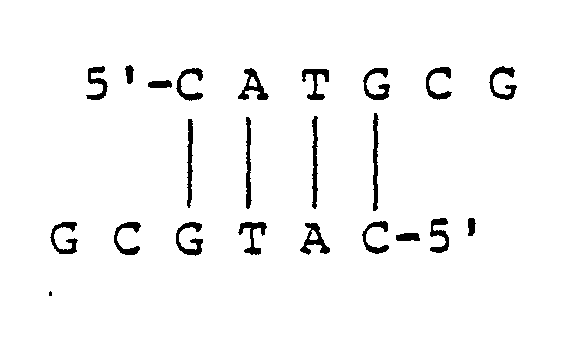
Cette complémentarité permet à partir d'un seul brin de reconstruire l'autre que ce soit in vivo lors de la réplication, ou in silico pour retrouver les informations placées sur l'autre brin. Un algorithme de complément prend en entrée une séquence et retourne en sortie sa séquence complémentaire. Par convention, toutes les séquences sont écrites dans le sens 5'-3'. Par conséquent une fois le brin complémentaire reconstitué sous la forme 3'-5' l’algorithme doit l'inverser.
Ainsi, dès qu'on analyse une séquence, on s’intéresse aussi à son complément car il peut contenir des informations importantes (un gène, une séquence de régulation, etc…), c'est donc une famille d'algorithmes essentielle en bioinformatique.
L'algorithme du jeune bioinformaticien (noob)
Je pense ne pas me tromper en disant que votre premier algorithme de complément inverse ressemblait sûrement à ceci (écrit en pseudo-code pour ne froisser personne) :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fonction rev_comp(seq): pour chaque nuc dans seq : si nuc == "A": resultat += "T" sinon si nuc == "C": resultat += "G" sinon si nuc == "G": resultat += "C" sinon nuc == "T": resultat += "A" resultat = inverse(resultat) retourne resultat |
Cet algorithme est juste, il donnera le bon résultat, mais n'en existe-t-il pas de plus performant ? Car oui, si vous appelez deux fois la fonction dans l'ensemble de votre programme, perdre un peu de temps ce n'est pas très grave, mais si vous l’appelez plus de dix mille fois comme quand vous travaillez sur des données NGS ça peut rapidement devenir limitant.
Comme chacun le sait le travail principal d'un algorithmicien est de découper son problème jusqu’à ce qu'il devienne ridiculement simple, j'ai donc découpé le problème en deux : d'un côté le complément et de l'autre l'inversion.
Présentation des algorithmes de complément (bien barbu ou pas)
L'algorithme de complément va prendre en entrée un nucléotide et renvoyer son complément.
L'algorithme naïf (comp_naif)
On va reprendre la sous-partie complément de l'algorithme naïf présenté plus haut.
|
1 2 3 4 5 6 7 8 9 |
fonction comp(nuc): si nuc == "A": return "T" sinon si nuc == "C": return "G" sinon si nuc == "G": return "C" sinon : return "T" |
Rien de bien compliqué, juste une série de si et on retourne la bonne valeur dès que possible, mais attention, si jamais on nous passe une lettre qui n'est pas un nucléotide, on renverra systématiquement un T. Il faudra probablement adapter votre algorithme en fonction des nucléotides présents dans vos jeux de données, il existe de nombreux cas où votre séquence ne contiendra pas que des A, des C, des T ou des G, on peut avoir des X, des N, des I, des B, je vous invite à aller consulter l'alphabet IUPAC pour l'ensemble des lettres possibles et leur signification.
L'algorithme de correspondance (comp_hash)
Cet algorithme se base sur une table de correspondance (ou table de hachage) : pour chaque nucléotide, on associe via la table de correspondance son complément. Sans plus attendre voici l'algorithme.
|
1 2 3 4 5 6 7 |
nuc2nuc{'A'} = 'T'; nuc2nuc{'T'} = 'A'; nuc2nuc{'C'} = 'G'; nuc2nuc{'G'} = 'C'; fonction comp(char nuc): retourne nuc2nuc{nuc} |
Petite subtilité dans l'exemple ci-dessus, on déclare la table de correspondance à l'extérieur de la fonction pour éviter de la recréer à chaque appel. A part cela, il n'y a pas grand-chose de compliqué, cet algorithme est assez simple.
Voici cependant une précision sur le fonctionnement d'une table de correspondance :
- la clef est transformée en valeur par une fonction de hachage
- si la valeur n'existe pas dans la table, création de la case et ajout de la valeur associée
- si la valeur existe déjà dans la table, gestion de collision (qui va exiger un grand nombre d'opérations)
Je vous invite à lire l'article wikipedia sur les tables de hachage pour plus de précision. Ce qu'il est important de retenir, c'est qu'une table de correspondance fonctionne comme un tableau, mais est un peu plus longue a l’exécution.
L'algorithme du tableau vide (comp_tab)
Vous savez que dans votre ordinateur les lettres ne sont que des nombres et qu'il existe différents types d'encodage des caractères. Mais celui qui est le plus souvent utilisé à l'heure actuelle (même s'il est de plus en plus remplacé par d'autres) est l'encodage ASCII.

Grâce à la jolie table on découvre que 'T' majuscule vaut 84, donc si on demande la case T d'un tableau on demande la 85ᵉ case du tableau (rappel : Dans les langages informatiques sérieux les tableaux commencent à l'indice zéro).
|
1 2 3 4 5 6 7 |
nuc2nuc['A'] = 'T'; //Dans la casse de valeur 'A' = 65 on stocke la lettre 'T' nuc2nuc['T'] = 'A'; nuc2nuc['C'] = 'G'; nuc2nuc['G'] = 'C'; fonction comp(nuc): retourne nuc2nuc[nuc] |
En C et en C++ la traduction de la lettre en sa valeur ASCII se fait automatiquement, dans d'autres langages (notamment Python) vous risquez de devoir utiliser des fonctions spéciales. Le tableau créé va occuper 85 cases mémoire nécessaires pour stocker un char, alors qu'on va n'en utiliser que 4 : l'algorithme n'est pas optimal dans son usage de la mémoire.
L'algorithme du polynôme de degré trois (comp_pol3)
Nous savons que chaque lettre est associée à un nombre, on peut supposer qu'il existe une fonction mathématique qui associe la valeur de 'A' à la valeur de 'T', la valeur de 'T' à la valeur de 'A', etc… . On cherche donc une fonction qui, pour les nombres [65, 67, 71, 84], associe les nombres [84, 71, 67, 65]. Les mathématiciens ont un super outil pour trouver ce type de fonction, ça s'appelle une interpolation de Lagrange, je vous épargne les calculs mais le résultat correspond à ce polynôme d'ordre 3 :
|
1 |
f(x) = -0.0456259 * base³ + 10.17873 * base² - 753.80732 * base + 18606.353 |
On peut se dire qu'on a juste à mettre tout ça dans le code sans se poser de question, mais il y a un petit truc cool. Comptons le nombre d'opérations à effectuer pour transformer un nucléotide en son complément : on a 8 multiplications et 3 additions. Bien évidement, il existe une solution pour réduire ce nombre d'opérations, et elle nous vient des vieux mathématiciens : on l'appellera la méthode de Horner (même si cette appellation est discutée). Elle consiste essentiellement à réécrire le polynôme sous une autre forme pour réduire le nombre d’opérations.
|
1 |
f(x) = (((-0.045625 * base + 10.1787) * base) - 753.8) * base + 18606) |
On a réduit le nombre d’opérations à 3 multiplications et 3 additions, c'est peut-être un détail pour vous mais pour votre CPU, ça veut dire beaucoup.
|
1 2 |
fonction comp(nuc): retourne (((-0.045625 * nuc + 10.1787) * nuc) - 753.8) * nuc + 18606) |
On a fini avec les différents algorithmes de complément. On a donc 4 algorithmes. Voici une petite liste récapitulative de leurs avantages et leurs inconvénients :
- comp_naif :
- Avantage : simple, pas d'usage mémoire
- Inconvénients : la complexité et longueur du code qui augmente beaucoup avec le nombre de lettres à gérer
- comp_hash :
- Avantage : rien de particulier
- Inconvénients : usage mémoire non nul, performance dépendante de la fonction de hachage utilisée
- comp_tab :
- Avantage : une seule opération quel que soit le nombre de lettres à gérer
- Inconvénients : usage mémoire important par rapport aux autres algorithmes (faire attention pour l'embarqué)
- comp_pol3 :
- Avantage : la classe de faire des maths, aucun usage mémoire
- Inconvénients : nombre d'opérations constant mais nécessite de recalculer la fonction si l'on veut supporter de nouvelles lettres, et le polynôme sera de degré nombre de lettres — 1
Les algorithmes d'inversion (il ne faut pas avoir Alzheimer)
Pour que vous compreniez bien cette partie il va falloir une petite explication sur comment fonctionne votre ordinateur. Il existe plusieurs zones où votre ordinateur stocke les variables qu'il utilise :
- le cache CPU, une zone mémoire très petite, où l'on stocke les variables qui sont utilisées par les opérations en cours (les 2 nombres de l’addition qu'on effectue par exemple)
- la mémoire RAM où sont stockées toutes les données sur lesquelles le programme travaille
- le disque dur où sont stockées toutes les autres données de façon plus pérenne
C'est un résumé très grossier, mais ce qu'il est important de noter c'est que tous ces espaces ont des caractéristiques différentes en termes de temps d'accès, le plus rapide étant le cache CPU, suivi de la mémoire RAM, puis enfin le disque dur (source). On peut aussi dire que lire une valeur est plus rapide que l'écrire, du moins en ce qui concerne la mémoire RAM (source). Encore une chose avant d'écrire dans la mémoire, il faut demander à avoir accès à cette zone mémoire (pour ne pas piquer celle de quelqu'un d'autre), on dit alors qu'on alloue cette zone mémoire à notre programme, cette opération prend évidement du temps.
L'algorithme d'inversion fait un peu plus qu'inverser la séquence, il construit la séquence de qui va contenir le complément. Nous allons donc considérer qu'il existe une fonction nuc2nuc(), qui prend en paramètre un nucléotide et renvoie son complément.
Gestion naïve de la mémoire (rev_naif)
La gestion naïve reprend le code du jeune bioinformaticien vus précédemment mais avec quelques améliorations.
|
1 2 3 4 5 |
fonction rev_naif(seq): pour nuc dans seq resultat = nuc2nuc(nuc) + resultat retourne resultat |
Si on regarde précisément ce qui se passe à chaque tour de boucle, on lit un nucléotide et on crée une nouvelle chaîne de caractère avec la concaténation de son complément et la chaîne résultat. On peut traduire en disant qu'on écrit dans la mémoire RAM n chaînes de caractères de taille 1 à n (pour n = taille de notre séquence).
Réservation de l'espace mémoire nécessaire à l'avance (rev_allocate)
Écrire en mémoire plusieurs fois la même information et une très mauvaise idée, mais si on alloue directement l'ensemble de la chaîne de caractères dès le début, on écrira qu'une seule fois chaque nucléotide.
|
1 2 3 4 5 6 7 |
fonction rev_allocate(seq): resultat = 'A' * taille_de(seq) pour i allant de 0 à taille_de(seq) - 1 : resultat[taille_de(seq) - i] = nuc2nuc(seq[i]) retourne resultat |
On alloue l'ensemble de la chaîne, et on inscrit les compléments depuis la fin.
Pourquoi réserver de la mémoire ? On en a déjà ! (rev_switch)
C'est une bonne question. On a déjà une chaîne de caractères qui fait la bonne taille, pourquoi ré-allouer une chaîne de la même taille ? Utilisons celle à disposition.
|
1 2 3 4 5 6 7 8 9 |
fonction rev_switch(seq): pour debut = 0 fin = taille_de(seq) tant que debut < ;= fin : tmp = nuc2nuc(seq[begin]); seq[begin] = nuc2nuc(seq[end]); seq[end] = tmp ; debut = debut + 1 fin = fin - 1 retourne seq |
Cet algorithme prend les deux cases extrêmes, calcule leur complément et les échange, et continue en progressant vers le centre, on n'alloue aucune mémoire, donc on gagne du temps. Mais ce gain de temps a un coût. En effet, on modifie la chaîne de caractères d'origine, ce qui peut éventuellement poser problème.
Allez, une petite liste récapitulative des avantages et des inconvénients des algorithmes d'inversion :
- rev_naif :
- Avantage : aucun
- Inconvénients : réalise beaucoup d'écritures
- rev_allocate :
- Avantage : on écrit le reverse complément une seule fois
- Inconvénients : on alloue une deuxième plage mémoire
- rev_switch
- Avantage : aucune allocation
- Inconvénient : modifie la chaîne de caractères d'origine
Nous avons vu tous les algorithmes, je vais maintenant vous présenter les résultats que j'ai obtenus, mais tout d'abord un petit point sur le protocole de test.
Le protocole de test (vachement original comme titre)
Vous trouverez l'ensemble du code source et des scripts utilisés pour obtenir les résultats présentés (et même plus) dans ce dépôt Github.
J'ai implémenté l'ensemble des algorithmes de complément et d'inversion de façon à pouvoir les combiner, nous avons donc 12 algorithmes différents. Ils ont été implémentés dans le langage C++, et peuvent éventuellement être généralisés à d'autres langages mais il faut rester prudent notamment avec les langages interprétés (Dinopython, Python, Perl, etc.).
Le jeu de test est composé de séquences d'ADN générées aléatoirement, d'une longueur comprise entre 10 et 10 000 nucléotides, avec des GC% compris entre 0 et 100 % avec un pas de 5 %.
Mon programme prend en entrée deux paramètres : le nombre de fois qu'on va rappeler chaque fonction, et la séquence à utiliser. J'ai paramétré les scripts d'appel pour que :
|
1 |
taille de la séquence * nombre de répétition = 10 000 000 |
En sortie, les programmes me fournissent la somme des temps de calcul de chaque fonction, sous forme de tableau CSV.
|
1 2 |
r_allo_c_hash,r_naif_c_hash,r_switch_c_hash,r_allo_c_naif,r_naif_c_naif,r_switch_c_naif,r_allo_c_pol3,r_naif_c_pol3,r_switch_c_pol3,r_allo_c_tab,r_naif_c_tab,r_switch_c_tab 113,191,47,67,174,37,70,181,40,66,176,35 |
J'ai appelé ce programme dix fois pour pouvoir avoir une moyenne pour chaque algorithme, pour chaque taille de séquence et pour chaque GC%.
Résultat
Les résultats présentés ont été obtenus sur un ordinateur portable avec un Intel core I3 3110M cadencé a 2.40 GHtz, et propulsé par une Fedora 22. Ils sont cohérents avec des résultats obtenus sur un autre ordinateur lui aussi d'architecture x86.
Quel est le meilleur algorithme en fonction du GC% ?
On s'attend à ce que le seul algorithme impacté par les variations du GC% soit l'algorithme naïf. En effet, si la séquence n'est composée que de A et que le premier if test si le nucléotide est un A, alors on effectuera qu'une seule opération, mais si c'est la dernière, on effectuera quatre opérations.

Mis à part l'algorithme de hachage, tous les autres ne semblent pas impactés par le taux de GC, ce qui contredit notre hypothèse. Peut-être que l’algorithme de hachage utilisé par la bibliothèque standard C++ provoque une collision entre deux nucléotides.
Évolution par rapport à la taille de la séquence
Le taux de GC n'a pas d’impact important sur les temps de calcul de nos algorithmes, mais on se doute que la taille des séquences posera problème. Notamment pour l'algorithme naïf d'inversion.

La longueur des séquences en abscisse suit une échelle logarithmique, les courbes ont l'allure d'une exponentielle, on a donc une croissance quadratique des temps de calcul, ce qui est cohérent avec notre réflexion sur l'algorithme d'inversion naïf.
Évolution pour chaque algorithme d'inversion
Est-ce qu'utiliser un algorithme d'inversion qui n'est pas naïf aide à réduire l'augmentation du temps de calcul ?

La réponse est évidemment oui, l'augmentation du temps de calcul n'est plus quadratique, ce qui est une très bonne chose. Ce graphique ne nous permet pas de savoir lequel des deux algorithmes est le plus performant.

Tout d'abord un petit point sur l'allure des courbes : avec l'augmentation de la taille des séquences, les temps de calcul diminuent, ceci est lié à notre protocole de test. On lance plus de fois l'algorithme quand la séquence est plus courte, on peut imputer ce phénomène aux nombreux appels de fonctions et d'allocations mémoire.
Logiquement, l'algorithme le plus performant est celui qui ne fait pas d'allocation mémoire.
Conclusion
Pour conclure sur quel est le meilleur algorithme de complément inverse, voici un petit récapitulatif de leurs performances :
- Algorithme de complément :
- En termes de temps de calcul :
- premier comp_tab
- second comp_naif
- troisième comp_pol3
- quatrième comp_hash
- En termes de consommation mémoire
- premier comp_naif et comp_pol3
- second comp_hash
- troisième comp_tab
- En termes de temps de calcul :
- Algorithme d'inversion en termes de temps
- premier rev_switch
- second rev_allocate
- troisième rev_naif
Si l'on veut l'algorithme le plus performant, en temps de calcul, il faut utiliser comp_tab et rev_switch, mais si on ne veut pas allouer de mémoire en plus, il faut utiliser comp_naif et rev_switch. Bien évidement ces choix sont à vérifier et moduler en fonction de votre cas particulier, mais il me semble que ce n'est pas une mauvaise chose de s'interroger sur quel algorithme on utilise pour ce problème qui paraît simple.
J’espère que cet article vous aura intéressé et que vous serez vigilant la prochaine fois que vous écrirez un algorithme de complément inverse. Si jamais vous trouviez d'autres façons d'écrire votre complément inverse (), vous pouvez les présenter dans les commentaires et/ou faire une pull request sur le projet git bench_rev_comp. Et s'il existe d'autres problèmes classiques de la bioinformatique dont vous souhaiteriez connaître les solutions, parlez en aussi en commentaire, je serai ravi de me pencher dessus.
Remerciement :
Je tiens à remercier : Pierre Peterlongo, Lucas Bourneuf, Pierre Vignet, les membres de mon master qui ont supporté mes mails, je remercie très sincèrement tous les relecteurs qui m'ont grandement aidé dans la rédaction de cet article : Mathurin, m4rsu, Norore, Hedjour, lelouar, Sacha Schutz, ZaZo0o, Kumquatum.
Laisser un commentaire