

Qui sommes nous ?

Une communauté d'étudiants et de professionnels

Une base d'articles libres pour tous niveaux

Des salons de discussion actifs au quotidien
-
Packrat ou comment gérer ses packages R par projet
 Lire la suite : Packrat ou comment gérer ses packages R par projet
Lire la suite : Packrat ou comment gérer ses packages R par projetJe vais m'arrêter là, je pense que vous avez compris que la gestion de packages sous R est une source d'erreurs faciles. Mais pas d'inquiétude : Packrat fait tout ça , Packrat est simple, Packrat vous veut du bien ! Packrat ? Kézako ? Packrat c'est un petit package R. "Encore un ?!" vous allez me dire, oui mais il […]
-
Comment fixer les problèmes de déploiement et de durabilité des outils en bioinformatique ? Indice : conda !
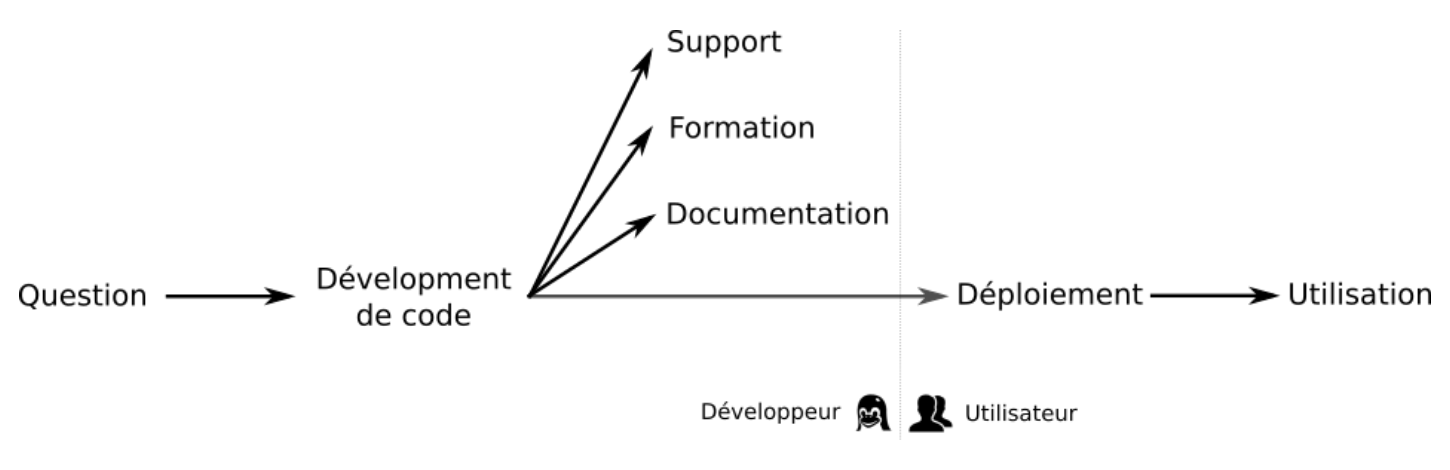 Lire la suite : Comment fixer les problèmes de déploiement et de durabilité des outils en bioinformatique ? Indice : conda !
Lire la suite : Comment fixer les problèmes de déploiement et de durabilité des outils en bioinformatique ? Indice : conda !La diversité des questions que se posent nos amis biologistes entraîne une diversité des données : génomiques, images, etc. De plus, ces données sont générées à des vitesses folles. Pour manipuler les données et extraire les informations utiles, des solutions et outils bioinformatiques sont nécessaires. De nombreux outils existent déjà pour répondre à de nombreuses questions. […]
-
Conda le meilleur ami du bioinformaticien
 Lire la suite : Conda le meilleur ami du bioinformaticien
Lire la suite : Conda le meilleur ami du bioinformaticienConda, le meilleur ami du bioinformaticien Conda est un package manager écrit en python, comme pypi. Mais contrairement à celui-ci, il permet d'installer des programmes écrits dans d'autres langages. Notamment vos outils bioinformatiques préférés par l’intermédiaire du dépôt bioconda. C'est-à-dire que tous vos outils, que ce soit samtools, bwa, bowtie, trimmomatic, fastqc et j'en passe, […]
-
Petit panel des journées bioinformatiques organisées par les masters en France !
 Lire la suite : Petit panel des journées bioinformatiques organisées par les masters en France !
Lire la suite : Petit panel des journées bioinformatiques organisées par les masters en France !En collaboration avec JeBiF et dans le cadre des bioinformations , nous mettons aujourd'hui des initiatives locales de masters à l'honneur ! Plusieurs masters ont, petit à petit, structuré leurs activités et créé des journées dédiées à la bioinformatique. Nous partagerons (sans modération 😉 ) les retours que nous ont fournis 3 villes : Rennes, Montpellier et Bordeaux. Chacun de […]
-
Tour d'horizon des outils de visualisation des réseaux biologiques
 Lire la suite : Tour d'horizon des outils de visualisation des réseaux biologiques
Lire la suite : Tour d'horizon des outils de visualisation des réseaux biologiquesAprès les différentes méthodes d'analyse et de représentation de réseaux métaboliques biologiques, je vais vous parler des différents outils de visualisation. Car oui, la visualisation d'un réseau ou de ses sous-parties peut être le début de son analyse, car elle permet de se rendre compte de sa topologie, de sa complexité, sa connectivité… En biologie, on peut […]
-
Dessiner vos gènes à partir d'un GFF3
Lire la suite : Dessiner vos gènes à partir d'un GFF3Je découvre à l'instant genometools, un outil multifonction qui est capable de générer une image représentant des annotations sur un génome de référence. Idéal par exemple, si vous voulez vous passer d'un genome browser comme UCSC ou Ensembl pour incruster des images dans votre rapport. Installation Vous pouvez récupérer et compiler le code source depuis le site officiel. Pour […]
-
LaTeX : les flottants !
 Lire la suite : LaTeX : les flottants !
Lire la suite : LaTeX : les flottants !Chose promise, chose due dans le précédent article voilà les flottants dans LaTeX Les flottants sont l'ensemble des éléments qui perturbent le flot du texte (pour faire simple) et désignent classiquement les tables et les figures ;on peut définir des environnements custom de flottants, mais on y reviendra dans un autre article ;). Les flottants « nagent » dans le […]
-
2017, on y est !
 Lire la suite : 2017, on y est !
Lire la suite : 2017, on y est !L'ensemble de l'équipe de bioinfo-fr.net vous souhaite une excellente année 2017 et plein de réussites pro et perso (oui, on a attendu le dernier jour de janvier pour vous dire ça 🙂 ). Nous avons prévu quelques nouveautés à venir dans le courant de l'année. Nous essayons de faire au mieux et au plus rapide […]
Articles les plus lus ces 7 derniers jours



Les salons de discussion :


La boutique

Quelques liens
Étiquettes
ADN analyse base de données bioinformatique code concours conférence débutant Découverte edito emploi formation Génomique Interview JeBiF JOBIM master modélisation outil programmation Python R Recherche rentrée script SFBI statistiques séquençage tutoriel vacances visualisation