

Depuis quelques années, le domaine du séquençage de l'information génétique est rentré dans une nouvelle ère : “le séquençage de seconde génération”. Cette avancée technologique a permis une analyse plus en profondeur de l'ADN et l'ARN. Nous pouvons citer parmi ces nouvelles technologies le ChIP-seq (Chromatine Immuno Precipitation sequencing) ou RNA-seq (Séquençage à ARN).
Le projet de thèse que je mène en ce moment porte sur l'étude de l'évolution de l'épissage alternatif ainsi que ses éléments régulateurs chez les vertébrés. Pour mener à bien cette étude nous avons récemment généré dans notre laboratoire une très grosse quantité de données de séquençage à ARN pour différents tissus chez plusieurs espèces. Ainsi, je profite de l'opportunité de publier chez bioinfo-fr pour vous présenter le fonctionnement du séquençage à ARN ainsi que l'analyse des résultats obtenus par cette méthode.
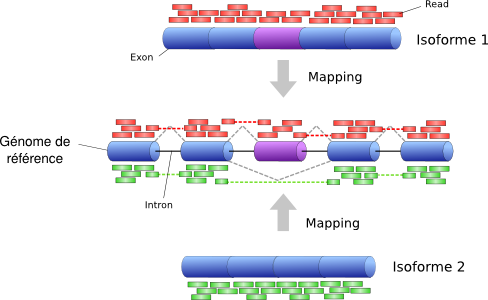
Le séquençage à ARN comme son nom l'indique nous permet d'obtenir toutes les séquences en ARN présentes à un moment donné dans un tissu. Pour cela, il faut tout d'abord extraire les séquences d'ARN pour le tissu étudié. Une fois ces séquences extraites, elles sont re-transcrites en ADN complémentaire (ou cDNA) par l'intermédiaire d'une transcriptase-inverse. Comme il n'est pas possible de séquencer directement toutes les chaînes nucléotidiques d'ARN en une seule fois du fait de leur longueur, elles sont partagées en un nombre de petites séquences de taille identique appelées reads. Cette taille était au préalable assez petite mais atteint aujourd'hui plus de 200 paires de bases pour les derniers séquenceurs comme Illumina HiSeq2000. La longueur de ces reads est importante car elle joue un rôle essentiel pour l'étape suivante qui consiste à "mapper" (de se positionner dans le génome) ces derniers sur un génome de référence (cf. figure). Plus les reads seront petits, plus ils auront de chances (ou de risques) de mapper à plusieurs endroits du génome. Comme vous le savez tous, la séquence de l'ARN messager mature contient uniquement des exons, ainsi les reads obtenus ne peuvent mapper uniquement que sur des régions exoniques. Pour détecter les introns, il faut étudier les reads qui se situent sur deux exons qui se suivent. L'alignement et le mapping sont les étapes préliminaires essentielles à l'analyse des données obtenues. Par la suite il est possible de détecter les différents isoformes pour un même gène ou les niveaux d'expressions de ces gènes.
Dans la figure suivante, les reads de deux isoformes sont représentés de différentes couleurs. Il est possible de visualiser leur mapping sur le génome de référence.
Les données obtenues en sortie du séquenceur se présentent sous la forme d'un fichier au format fastQ. Ce fichier atteint généralement une taille de plusieurs gigaoctets et contient les informations pour tous les reads ayant mappé sur le génome. Les reads qui ne mappent sur aucune partie du génome sont automatiquement rejetés de l'analyse. Chaque read est représenté par 4 lignes dont les attributs sont les suivants :
- ligne 1 : contient l'identifiant pour le read et commence par un @. L'identifiant représente les coordonnées de notre échantillon dans le séquenceur. Un séquenceur peut analyser plusieurs échantillons en même temps, pour cela chaque échantillon possède des coordonnées pour les reconnaître.
- linge 2 : correspond à la séquence du read
- ligne 3 : commence par un « + » et est souvent suivie de l'identifiant. Cette ligne peut contenir une description en rapport avec le read si nécessaire.
- ligne 4 : contient la valeur de qualité pour chaque nucléotide du read. Pour la qualité, différentes méthodes existent : Phred33, Phred64 ou Solexa.
Pour plus de détails, je vous invite aussi à consulter l'excellente page Wikipedia à propos du format fastQ.
Une fois les données récupérées, l'analyse peut se faire de différentes façons selon les résultats attendus. Voici une liste non-exhaustive d'outils qui sont fréquemment utilisés dans l'analyse des données de RNA-seq :
- Bowtie : cet outil se charge de l'alignement des reads obtenus après l'analyse.
- Tophat : pour la détection de jonctions. Il est ainsi possible de détecter les introns ainsi que les sites d'épissage.
- Cufflinks : utilisé pour la définition des niveaux d'expression des gènes.
- Galaxy : ce service web est tout simplement exceptionnel. Quasiment tous les outils pour l'analyse de données de séquençage y sont présent.
- GDV : Genome Browser, dont le projet est mené par notre cher Yohan Jarosz 🙂 Il permet une visualisation graphique des données.
- UCSC : assez similaire à GDV.
- Sinon il y a les bons vieux scripts fait-maison en Python ou Perl :).
L'analyse de ces données de séquençage à ARN n'est pas une chose facile, il faut savoir gérer des fichiers de grosse taille ainsi que de l'analyse très précise. Il arrive même de devoir se concentrer sur certains reads en particulier parmi les millions de reads présent dans l'analyse. Cependant les outils deviennent aussi de plus en plus puissants pour gérer ce type de données. Cela restera vrai jusqu'à la prochaine génération de séquençage 🙂
Laisser un commentaire